E'inutile addentrarsi negli "oscuri" meandri dell'assembler senza prima avere delle basi decenti, programmare in assembler non significa solamente imparare a pappagallo a usare determinate istruzioni..si le cose possono anche funzionare, ma per me come molti altri, programmare in Assembler significa prima di tutto sapere cosa si sta facendo, e come ogni singola istruzione influisce o viene influenzata dall'architettura...e più sapete COME funziona più sapete COSA state facendo e siete in grado di manipolare per raggiungere i vostri scopi...per questo cominceremo con la comprensione dei concetti fondamentali, in modo che poi siate capaci di localizzare e contestualizzare ogni singolo elemento effettuando i collegamenti neuronali del caso :P
Questi skill sono importanti perchè vi aiuteranno a vedere il computer e ogni programma in esecuzione con occhi diversi...e sono delle ottime basi che vi torneranno utili, sia che vogliate fare i programmatori, i sistemisti...
Prerequisiti: avere una conoscenza di base dei registri del microprocessore e delle operazioni fondamentali e che sappiate ad esempio la differenza tra un registro accumulatore e un registro di segmento. Darò per scontato che lo sappiate. Ovviamente, per una trattazione DETTAGLIATA di questi argomenti, vi rimando ai manuali intel o a qualche ricerca specifica su google.
Alcuni commenti tra parentesi sono di Ntoskrnl e sono indicati con ndnt. Ok, allora...Rock 'n Roll!
La segmentazione
E'un meccanismo per la gestione della memoria che permette ai programmatori di "partizionare" i loro programmi in "moduli" che operano indipendentemente l'uno dall'altro. Immaginiamo la memoria come un unico grande array di byte. In qualità di array, con un indice (l'indirizzo) si può selezionare un qualsiasi elemento di questo array. Chiamiamo questa modalità di indirizzamento Lineare (da qui Linear Address appunto) o Flat.
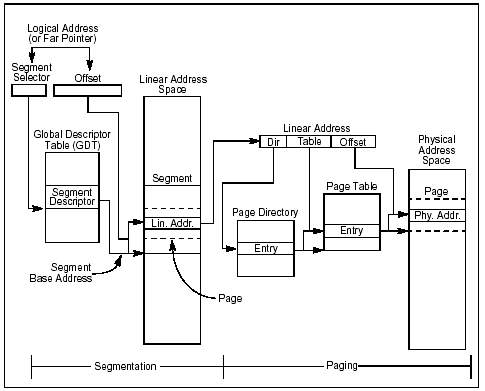
Dal manuale Intel (Basic Architecture): "Con la segmentazione, un registro di segmento di 16 bit contiene un puntatore (quindi un indirizzo) a un segmento di memoria fino a 64Kb (NdLonelyWolf: questo perchè essendo l'8086 un'architettura a 16 bit, per la grandezza del bus indirizzi, il numero massimo che può contenere è appunto 216 ed è questo il max numero di segmenti potenzialmente disponibili). Usando 4 registri di segmento alla volta i processori 8086/8088 sono capaci di indirizzare 256Kb senza switchare tra i segmenti.......Con il modello della memoria segmentata un programma vede la memoria come un gruppo di spazi di indirizzi indipendenti chiamati appunto Segmenti. Usando questo modello, codice, dati, stack sono tipicamente contenuti in segmenti diversi. Per indirizzare un byte in un segmento, un programma deve fornire un Logical Address(Indirizzo Logico) composto da un segmento selettore e un offset. Un indirizzo logico è spesso riferito come Far Pointer. Il segmento selettore identifica il segmento che deve essere acceduto e l'offset identifica un byte nello spazio di indirizzi di tale segmento...
Nonostante l'architettura segmentata, la memoria fisica presente sulla scheda madre viene comunque vista come un array lineare di byte per cui esisterà una funzione/meccanismo che convertirà un'indirizzo segmentato in uno lineare.
Internamente tutti i segmenti che vengono definiti per un sistema sono mappati nel Linear Address Space. Per accedere ad una locazione di memoria il processore traduce (in maniera trasparente) gli indirizzi logici in indirizzi lineari. La prima ragione per usare la segmentazione è per accrescere l'affidabilità dei programmi e dei sistemi. Ad esempio, mettendo lo stack in un segmento separato si evita che questo cresca nel codice o nei dati e sovrascriva i dati relativi.
Con il modello flat (che vedremo cmq dopo) o segmentato, il linear address space viene mappato nello spazio di indirizzi fisico del processore sia direttamente che mediante paging. Quando si usa il mapping diretto (paging disabilitato) ogni indirizzo lineare ha una corrispondenza 1:1 con un indirizzo fisico (e quindi questi indirizzi lineari vengono mandati sul bus indirizzi del processore così come sono, senza dover essere tradotti). Quando si usa il meccanismo di paging (anche esso trasparente) della IA-32 lo spazio di indirizzi lineare viene diviso in pagine, mappate nella memoria (virtuale).
Ogni indirizzo è rappresentato dunque come
segmento:offset
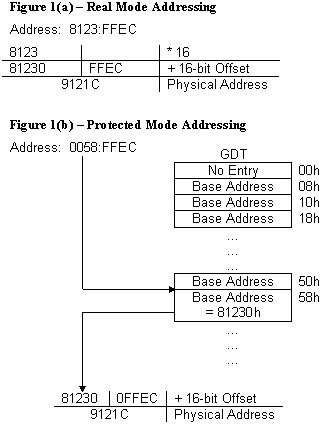
dove segmento e offset consistono sempre (su 8086) in un valore a 16 bit. In Real Mode (Modalità Reale), il valore del segmento è un indirizzo fisico che ha una relazione matematica col valore dell'offset. Insieme, segmento e offset creano, anzi DEVONO creare un'indirizzo fisico di 20 bit perchè tale è la grandezza del bus indirizzi.
Ma come fa il processore a combinare un segmento e un offset di 16 bit per formare un indirizzo di 20 bit da mettere sul relativo bus? Ecco come/cosa fa:
1. A scuola ci dicevano "si mette uno 0 in fondo all'indirizzo..." si è vero, il risultato è quello ma un momento ;)
Il processore shifta verso sinistra l'indirizzo del segmento (lasciando per questo 4 bit a zero), producendo così un indirizzo di 20 bit. Questa operazione corrisponde alla moltiplicazione dell'indirizzo del segmento per 16, ovvero 10 in hex infatti non serve la calcolatrice per fare 53C2 * 10 come da esempio sotto (in asm corrisponde a un SHL reg, 4 dove reg ovviamente è un REGistro e guarda caso 24 fa 16... un po'più esaustiva come spiegazione, non trovate? :P)
2. Il processore aggiunge questo indirizzo di segmento di 20 bit all'offset di 16 (che NON viene shiftato)
3. Il processore utilizza così l'indirizzo risultante di 20 bit chiamato indirizzo fisico, per accedere alla corrente locazione nello spazio di indirizzi di 1 megabyte (si 1 Mb. 2^20 boys)
Es.
53C2:107A
5 3 C 2 0 SHL reg, 4
+
1 0 7 A l'offset di 16 bit
--------------
5 4 C 9 A indirizzo fisico di 20 bit
Nota:Un'indirizzo fisico di 20 bit può essere specificato con 4096 segmento:offset diversi! Infatti gli indirizzi 0000:F800, 0F00:0800 e 0F80:0000 si riferiscono tutti allo stesso indirizzo fisico 0F800.
Questi concetti sono molto importanti, perchè riguardano molti aspetti della programmazione in asm, specialmente per gli indirizzi e i puntatori.
Ancora sulla segmentazione e paginazione dai manuali intel: La segmentazione provvede un meccanismo per isolare codice individuale, dati e stack in modo che più programmi (task) possano essere eseguiti sullo stesso processore senza interferire l'uno con l'altro. La paginazione fornisce un meccansimo per implementare una demand-paged convenzionale, un sistema di memoria virtuale dove sezioni dell'ambiente di esecuzione di un programma sono mappate nella memoria fisica quando necessario (Quando segmentazione e paginazione vengono combinate insieme, i segmenti possono essere mappati in pagine in molti modi)
Anche la paginazione può essere utilizzata per fornire isolamento tra task multipli (ogni segmento viene diviso in pagine solitamente di 4Kb che vengono memorizzate nella memoria fisica o eventualmente su disco). Le informazioni che il processore usa per mappare indirizzi lineari nei relativi indirizzi fisici e per generare eventuali Page-Fault vengono mantenute in "Page Directory" e un set di "Page Tables" in memoria, per tenere traccia delle pagine. In questo modo, quando un programma tenta di accedere ad una locazione nello Linear Address Space il processore usa la Page Directory e la Page Tables per *Tradurre* l'indirizzo lineare nel corrispondente indirizzo fisico.
Se la pagina richiesta non dovesse trovarsi nella memoria fisica il processore interromperebbe l'esecuzione del programma (generando una eccezione "Page-Fault, #PF"). L'Exception Handler per il Page-Fault la caricherebbe dal disco e il ritorno dall'Exception Handler farebbe riprendere l'esecuzione del programma.
Per minimizzare i cicli di bus richiesti per la traduzione degli indirizzi, le Page Directory accedute più frequentemente e le Page Tables entries sono cachate nel processore in dispositivi chiamati Translation Lookaside Buffers (TLBs). La famiglia P6 e processori Pentium hanno TLBs separate per cachare dati e istruzioni. L'istruzione CPUID può essere usata per determinare la grandezza del TLB del proprio processore. Le TLBs soddisfano molte richieste di lettura della Page Directory corrente e Page Tables senza richiedere un ciclo di bus, ciclo che occorrerebbe solo in caso di "cache miss" (NdLonelyWolf: ovvero quando non è presente nel buffer, ergo la pagina non è stata acceduta da un pezzo). Mentre esiste un modo per abilitare/disabilitare il paging (il bit 31 del registro di controllo CR0..Disponibile su tutti i processore IA-32 a partire dal 80386) non c'è alcun modo per disabilitare la segmentazione.....
La segmentazione fornisce un meccanismo per dividere lo spazio di memoria indirizzabile del processore (Linear Address Space) in spazi di indirizzi più piccoli protetti, chiamati appunto SEGMENTI. I segmenti possono essere usati per mantenere codice, dati e stack per un programma oppure per le strutture dati del sistema (come LDT o TSS). Se più di un programma è in esecuzione a ognuno di questi viene assegnato un suo set di segmenti. Il processore gestisce anche i limiti di questi segmenti e assicura che un programma non possa interferire con l'esecuzione di un altro scrivendo in un altro segmento. Il meccanismo di segmentazione permette anche di tipizzare i segmenti in modo che alcune operazioni su tali segmenti, possano essere ristrette o meno.
Il selettore è un identificatore unico del segmento. Provvede anche un offset in una descriptor table (ad esempio GDT) che a sua volta punta a una struttura dati chiamata Segment Descriptor. Ogni segmento ha un proprio segment descriptor che specifica BASE e LIMIT, i diritti di accesso e il livello di privilegio per il segmento (Ring 0-1-2-3), il tipo di segmento e la locazione del primo byte del segmento nello Linear Address Space (chiamato Base Address). L'offset viene poi aggiunto a questo indirizzo base per localizzare un byte all'interno del segmento. Base Address + Offset = Linear Address Space nello Linear Address Space del processore. (Un Physical Address - Indirizzo Fisico - viene definito come il range di indirizzi che il processore può generare sul suo bus indirizzi). Non vi spaventate...
Real Mode e Protected Mode
In real mode può essere eseguito un solo processo alla volta (niente multithreading quindi, ndnt) e gli indirizzi corrispondono sempre alla Reale locazione in memoria (indirizzi fisici volevo dire). Sempre dal Manuale Intel (spero di tradurre a modino ;P): Protected Mode usa i contenuti di un registro di segmento come selettori o puntatori a una tabella di descrittori. I descrittori provvedono un indirizzo a 24 bit, fino a 16Mb di memoria fisica, supporto per la gestione della memoria virtuale su un segmento basato su swapping e vari meccanismi di protezione. I meccanismi di protezione includono: Controllo dei limiti di un segmento, opzioni sui segmenti di read-only o execution-only, e fino a 4 livelli di privilegio (Anche se in pratica se ne usano solo 2, ndnt) per proteggere il codice del sistema operativo (gli osannati Ring) da interferenze. In aggiunta, hardware task switching e LDT (Local Descriptor Table) permettono al sistema operativo di proteggere le appplicazioni degli utenti l'una dalle altre. ...Per garantire la compatibilità, si può sempre usare la Real Mode, ma solo attivando la modalità Virtual 8086.
Quando si opera in protected mode tutti gli accessi alla memoria passano attraverso la GDT o la LDT. Queste tabelle contengono delle entries chiamate Segment Descriptor. Un segment descriptor fornisce l'indirizzo di base di un segmento e diritti di accesso, tipo e informazioni di uso. Ognuno di questi segment descriptor possiede un Segment Selector univoco associato. Il segment selector fornisce un indice nella GDT o LDT, un flag global/local (che determina appunto se il segment descriptor punta alla GDT o alla LDT) e informazioni sui diritti di accesso. Per accedere a un byte in un segmento, entrambi i segment selector e un offset devono essere forniti. Il segment selector fornisce l'accesso al segment descriptor per il segmento (nella GDT o LDT). Dal segment selector, il processore ottiene l'indirizzo base del segmento nel Linear Address Space. L'offset poi provvede la locazione del byte relativa al base address. Questo meccanismo può essere usato per accedere a qualsiasi segmento codice, dati, o stack valido nella LDT o GDT, in base all'accessibilità del segmento data dal CPL (Current Privilege Level) nel quale il processore sta operando (Il CPL è definito come livello di protezione del codice segmento in esecuzione). Il linear address della base della GDT è contenuto nel registro GDTR mentre quello della LDT nel registro LDTR (registri per i quali abbiamo istruzioni dedicate). In protected mode gli indirizzi non corrispondono direttamente alla memoria fisica. Il processore alloca e gestisce la memoria dinamicamente. Quindi se il codice e i dati di un prog occupano meno di 64K risiedono nello stesso segmento per cui basta solo l'offset per localizzare una variabile o un'istruzione. In caso contrario, se ad esempio il segmento data occupa 2 o più segmenti il programma dovrà specificare sia segmento che l'offset per localizzare una determinata variabile. (Questo problema non sussiste invece in uno spazio di indirizzi "flat" della modalità protetta a 32 bit) Con l'"avvento" dei processori in modalità protetta, l'architettura segmentata ebbe un altro scopo. I segmenti potevano separare blocchi differenti di codice o dati e proteggerli da interazioni indesiderate (e inoltre supportavano il modello di memoria flat). Quando un programma vuole accedere a un segmento quindi, "dietro le quinte", il segment selector per quel segmento deve essere stato caricato in uno dei registri di segmento. Così, sebbene un sistema possa definire migliaia di segmenti, solo 6 possono essere disponibili per un uso immediato. Gli altri segmenti sono resi disponibili con il caricamento del loro segment selector in questi registri durante l'esecuzione del programma. Ogni registro di segmento ha una parte "visibile" e una "nascosta" (la parte nascosta è qualche volta riferita come Descriptor Cache o Shadow Register).

(http://www.x86.org/articles/pmbasics/tspec_a1_doc.htm) Articolo molto interessante, spiega molto bene questo discorso del Segment Descriptor Cache accennando anche a come in Real Mode su 80386 si potrebbe avere un grosso data segment in read only di 4 Gb....Quando un segment selector viene caricato nella parte visibile di un registro di segmento, il processore carica anche la parte nascosta del registro di segmento con il base address, limit e le informazioni di accesso prese dal descrittore puntato dal selettore. Queste informazioni cachate nel registro di segmento (visibili e invisibili) permettono al processore di tradurre indirizzi senza cicli bus extra per leggere quelle informazioni dal descriptor (che volponi che sono ;D). L'indirizzo fisico presentato sul bus address della CPU è formato con l'aggiunta dell'offset (16 o 32 bit) al base address presente nella descriptor cache
http://www.x86.org/ddj/aug98/aug98.htm Descrive in maniera decisamente migliore questa Descriptor Cache, altra lettura consigliata se proprio non avete niente di meglio da fare. C'è un paragrafetto "Descriptor-Cache Registers In Real Life"...ci sono modi diversi per prendere vantaggio dai registri segment-descriptor cache. System-management mode (SMM) ti da il controllo diretto su ogni campo nella segment-descriptor cache. (See my DDJ January >/ March/May 1997 columns for an in-depth look at System Management Mode.) Anche In-circuit emulators (ICEs) permette di prendere il controllo diretto su ogni campo nella segment-descriptor cache. (Refer to my DDJ July /September /November 1997 columns for information on in-circuit emulation.)
L'autore racconta di come gli capita a volte di sbagliare qualcosa nella dichiarazione di una sua GDT usando un base address errato ad esempio, e debuggando con ICE (uhmmmm pensate anche voi quello che penso io? :P) carica e può modificare determinati valori direttamente li. L'articolo prosegue con quella che è stata definita Unreal Mode, cosa che ha attirato la mia attenzione. "...l'uso di queste tecniche per la manipolazione della Segment-Descriptor Cache può essere una sfida. Comunque, esiste un altro modo programmatico di far funzionare questa Segment-Descriptor cache, creando una modalità operativa di CPU chiamata Unreal Mode. Unreal Mode viene creata quando un segmento in modalità reale si ritrova con un segment limit di 4 Gb. Unreal Mode può essere creata senza l'uso di debugger hardware o programmazione in SMM con un semplice programma in assembler. Immagina un programma che inizia in modalità reale e poi salta in modalità protetta. Una volte in protected mode il programma carica tutti i registri di segmento con descrittori contenti segment limits di 4 Gb. Dopo aver settato i segment limits ritorna immediante in modalità reale senza ripristinare i registri di segmento contenenti segmenti di 64Kb (compatibili modalità reale). Una volta in modalità reale il segment limit resterà quello di 4Gb. A quel punto i programmi DOS potrebbero trarre vantaggio dell'intero spazio di indirizzamento a 32 bit senza programmazione in protected mode.
Unreal Mode è stata usata comunemente da quando fu scoperta sull'80386. Questa modalità è così comunemente usata infatti, che Intel è stata forzata a supportarla come strascico del comportamento dell' 80x86 anche se non è mai stata documentata. Giochi e Memory Managers spesso traggono vantaggio da questo. Source Code disponibile su DDJ (see "Resource Center,") oppure ftp://ftp.x86.org/dloads/UNREAL.ZIP oppure qua http://www.x86.org/ftp/dloads/unreal.zip Tuttavia, entrare nei meriti di SMM e ICE esula dagli scopi di questo tutorial, forse pubblicherò qualcosa più in la, visto che il sottoscritto è curioso e vuole approfondire.
Memory Management Register (Sempre dai manuali Intel, Vol.3)
Il processore provvede 4 registri per la gestione della memoria (GDTR, LDTR, IDTR e TR) che specificano le locazioni delle strutture dati della gestione della memoria segmentata. (NdLonelyWolf: per la cronaca, esistono anche altri 2 gruppi di registri, i Control Register e i Debug Register che per ora almeno non prenderemo in esame, ma MOLTO importanti). Istruzioni speciali sono incaricate di leggere e scrivere in questi registri.

Il registro GDTR contiene il base address di 32 bit e il limite di 16 bit per la GDT. Il base address specifica il linear address del byte 0 nella GDT; limite specifica il numero di byte nella tabella....All'accensione o al reset del processore, il base address è settato al valore di default 0 e il limite a FFFFh. Un nuovo indirizzo base deve essere caricato nel GDTR come parte del processo di inizializzazione del processore per le operazioni in protected mode.
Il registro LDTR contiene il selettore del segmento di 16 bit, il base address di 32 bit, il limite del segmento di 16 bit e glil attributi del descrittore per la LDT. Questo base address specifica l'indirizzo lineare del byte 0 del segmento LDT; il limite del segmento specifica il numero di bytes nel segmento...il segmento che contiene la LDT deve avere un segment descriptor nella GDT...quando l'istruzione LLDT carica un segment selector nel LDTR, il base address, limit e gli attributi del descrittore vengono presi dal descrittore della LDT e caricati nel LDTR. Quando si verifica un task switch, LDTR è caricato automaticamente con il segment selector e il descrittore LDT per il nuovo task. I contenuti del LDTR non sono salvati automaticamente prima della scrittura delle nuove informazioni nel registro.
Il registro IDTR contiene il base address di 32 bit e il limit di 16 bit per la IDT. Il base address specifica l'indirizzo lineare del byte 0 della IDT e il limit il numero di byte nella tabella.
Il TR - Task Register contiene un segment selector di 16 bit, il base address di 32 bit, il limit di 16 bit e gli attributi del descrittore per il TSS (Task State Segment per il supporto del multitasking) del task corrente. Esso si riferisce a un TSS descriptor nella GDT. Il base address specifica l'indirizzo lineare del byte 0 del TSS; il limite del segmento specifica il numero di bytes nel TSS. Quando si verifica un task switch, il task register viene caricato automaticamente con il segmento selettore e il descrittore per il TSS del nuovo task. I contenuti del task register non sono salvati prima della scrittura delle informazioni del nuovo TSS nel registro.
Ancora (http://www.x86.org/articles/pmbasics/tspec_a1_doc.htm )
...in modalità protetta la segmentazione di memoria è invece definita da un set di tabelle (chiamate tabelle di descrittori) e i registri di segmento contengono puntatori a queste tabelle. Ogni entry in queste tabelle è di 8 byte, perciò i valori contenuti nei registri di segmento sono definiti in multipli di 8 (08h, 10h, 18h, etc.), questo implica un'eccezione quando si cerca di caricare un registro di segmento con un valore che non è un multiplo di 8.
Descriptor Tables e Segment Selectors
(http://microlabs.cs.utt.ro/~mmarcu/books/03/p_all2.htm)
I descrittori sono speciali strutture in memoria (grandi 8 byte) che descrivono un segmento e registrano i seguenti attributi di segmento:
- L'indirizzo fisico di partenza del segmento all'interno della memoria (32 bit)
- La lunghezza del segmento (20 bit)
- Informazioni addizionali come i diritti di accesso (il campo Descriptor Privilege Level, DPL) e il tipo di segmento (data, codice)
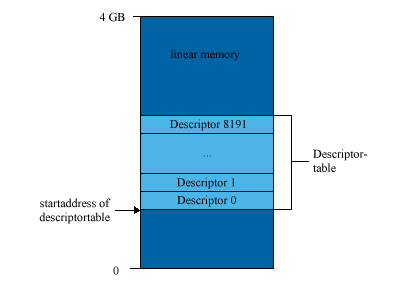
Poichè lo spazio per la selezione del descrittore all'interno del selettore è limitato solo a 13 bit una Descriptor Table può supportare solo 8192 descrittori (213= 8192). NdLonelyWolf: ma come 13 bit? non erano 16??? Il selettore, oltre a selezionare una Descriptor Table memorizza altre 2 informazioni importantissime (3 bit)! Il bit TI (Table Indicator) determina se il selettore si sta riferendo alla GDT o alla LDT. L'altro bit impiegato è RPL (Requested Privilege Level) e indica il livello di privilegio desiderato.
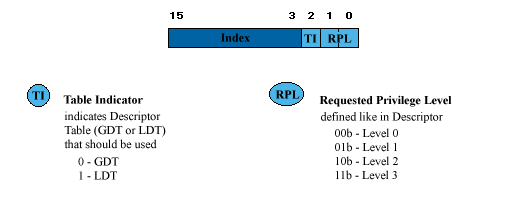
Facciamo un esempio: Selector: 02FBh
binary: 0000001011111011b -> Vedi Tabella qua sopra. Gli ultimi 3 bit ci dicono che si "parla" di GDT e che il RPL è Level 3. Inoltre la grandezza massima di una Descriptor Table è limitata a 64 KB (64 KB (65536) / 8 = 8192 possible, 8 byte long entries = 8192 Descriptors). Il processore differenzia tra almeno 2 tipi differenti di Descriptor Tables. Uno è la Global Descriptor Table (GDT) che è equalmente accessibile da tutti i processi/programmi, da qui infatti il nome global.
La GDT contiene informazioni di segmentazione che riguardano la grandezza, il punto di partenza e i diritti di accesso a un certo segmento.
Ogni sistema DEVE avere una GDT definita che può essere usata da tutti i programmi e task nel sistema. Opzionalmente possono essere definite una o più LDT (in questo caso la GDT deve contenere un descrittore per la LDT che può stare dovunque nella GDT. Se il sistema supporta LDT multiple ognuna deve avere un selettore e descrittore separato nella GDT). Per esempio, una LDT può esere definita per ogni task in esecuzione oppure più task possono condividere la medesima LDT. La GDT non è un segmento è piuttosto una struttura dati nel Linear Address Space L'altra tabella di descrittori è la Interrupt Descriptor Table (IDT) anch'essa disponibile per tutti i processi/programmi. Contiene degli speciali descrittori chiamati Gates o Gate-Descriptors. Un Gate-Descriptor viene usato per registrare un indirizzo di una Interrupt Routine in memoria. Un sistema operativo dovrebbe usare la IDT per fornire Exception Handlers per tutte le possibili eccezioni. La IDT si può comparare alla vecchia Interrupt Vector Table della Real Mode. Oltre le 2 Descriptor Table specificate sopra, c'è la possibilità di creare una Descriptor Table per ogni task. Questa speciale tabella viene chiamata Local Descriptor Table (LDT).
Fermiamoci un attimo, cerchiamo di digerire tutta sta roba. Dunque, è tutto chiaro fin qui? Capito la logica della protected mode, questa faccenda dei descrittori? Ma giustamente un programma per potervi accedere deve sapere DOVE andare a cercare in memoria questi descrittori. Queste informazioni sono mantenute in questi 3 nuovi registri. Oltre ai 3 nuovi registri abbiamo anche qualche istruzione nuova da imparare. Ma come si usano? Facciamo un esempio (per gli altri, google :P)
Global Descriptor Table
LGDT mem (LOAD GDT) si aspetta un puntatore (mem) alla seguente struttura:GDTSTRUC STRUC
Limit dw ?
BaseAddr dd ?
GDTSTRUC ENDS
SGDT mem (STORE GDT) memorizza il valore corrente del registro GDTR
nell'operando indicato. Ecco, siccome ero curioso di fare almeno una prova a usare uno di questi registri mi son codato un programmino idiota di poche righe che fa una SGDT e ne visualizza Base e Limit.
; 6/11/2004 ; Show SGDT Base and Limit with MessageBoxes ; ; Lonely Wolf - [email protected] .386 .model flat, stdcall option casemap :none include \masm32\include\windows.inc include \masm32\include\kernel32.inc includelib \masm32\lib\kernel32.lib include \masm32\include\user32.inc includelib \masm32\lib\user32.lib .data GDTR df 0 ; 6 byte = 48 bit MsgBoxC1 db "GDT Base", 0 MsgBoxC2 db "GDT Limit", 0 specB db "%.8X", 0 specL db "%.4X", 0 buffer db 8 dup (0) .code start: lea esi, GDTR SGDT fword ptr [esi] invoke wsprintf, addr buffer, addr specB, GDTR+2 invoke MessageBox, NULL, addr buffer, addr MsgBoxC1, MB_OK mov dx, word ptr GDTR invoke wsprintf, addr buffer, addr specL, dx ; Limit è di 16 bit invoke MessageBox, NULL, addr buffer, addr MsgBoxC2, MB_OK invoke ExitProcess,0 end startIl programmino mi mostra 2 MessageBox che mi dicono che Base = C25B000 e Limit = FFF. Ci dobbiamo credere?
Pensando a come verificarlo, mi ricordai del comando GDT del Softice... Fire up!
CTRL+D
GDT
Base = C25B000h Limit = 0FFFh
Direi che ci siamo! :)
Gates
Spendiamo ora due parole su questi "Gates" che sono stati rammentati poco fa. I processori Intel a partire dalla famiglia 80286 possiedono un concetto di protezione che impedisce tra le altre cose l'esecuzione del codice di un programma in un livello di privilegio (anello -> Ring) diverso da quello corrente (il CPL, Current Privilege Level). Questa abilità è importante per la stabilità dell'intero sistema. Un errore di programmazione in un basso livello di privilegio (diciamo più vicino all'utente) influenzerà solo il task corrente, e non l'intero sistema operativo. Tuttavia un applicazione di livello 3 potrebbe aver bisogno di usare una routine del sistema operativo (come una richiesta di memoria, aprire un file...) e per far questo sono nati questi "gates", ovvero una entry point verso i livelli bassi. La figura rende l'idea:
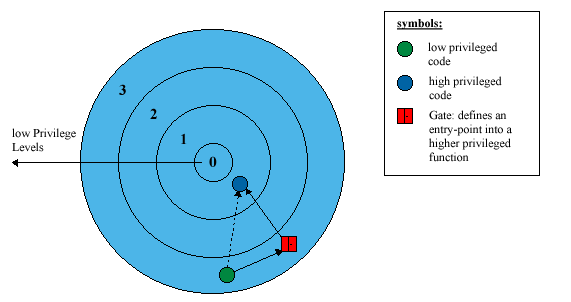
I Gates appartengo agli oggetti di sistema (e usano un proprio formato per i loro descrittori) che tuttavia non spiegheremo in questa sede.
Virtual Addressing
(http://microlabs.cs.utt.ro/~mmarcu/books/03/p_all2.htm) (NdLonelyWolf: Forse è un po'ridondante questo paragrafetto ma certe cose mi sembrano spiegate proprio bene e i disegnini son carini :P)
A differenza della Real Mode, il processore considera la memoria COME virtuale, nel senso che l'indirizzo fisico finale di memoria è sconosciuto a un programma in esecuzione e ogni accesso diretto alla memoria è prevenuto (NdLonelyWolf: anche se ci sono tecniche per farlo ugualmente, vedi sotto windows l'accesso a \device\PhysicalMemory...ma questa è un'altra storia..).
Un virtual address è costituito da una parte a 16 bit chiamata Selettore e da una parte a 32 bit Offset. Come in Modalità Reale, il valore a 16 bit del selettore deve essere prima caricato in un registro di segmento (CS, DS, ES, FS, GS) poi si potrà accedere alla memoria mediante l'offset. Il selettore comunque, non contiene l'indirizzo del segmento in memoria, ma un numero noto come Segment Descriptor. Tale descrittore registra l'indirizzo fisico di partenza così come la sua grandezza insieme a degli attributi addizionali. Il processore usa il selettore come indice in una tabella con i segmenti descrittori (Descriptor Table) per trovare l'indirizzo di partenza del segmento selezionato. Unendo così questi valori, l'indirizzo finale viene costruito e acceduto.
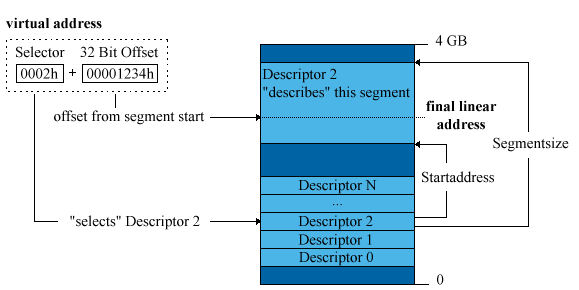
Guardate meglio la figura, non notate niente di strano?
Ve ne mostro un'altra sempre da quell'articolo su x86.org (http://www.x86.org/articles/pmbasics/tspec_a1_doc.htm):
Dal manuale Intel:La prima entry della GDT non è usata dal processore. Un segmento selettore che punta a questa entry della GDT (cioè, un segmento selettore con indice pari a 0 e il flag TI settato a 0) è usato come "Null Segment Selector". Il processore non genera un eccezione quando un registro segmento (Oltre ai registri CS o SS) viene caricato con un null selector. La genera invece quando un registro di segmento inizializzato con un null descriptor cerca di accedere alla memoria provocando una eccezione General Protection #GP. Un altro articolo su x86.org (http://www.x86.org/productivity/nulldescriptor.htm) spiega come questo potrebbe essere usato: "...Il Null descriptor è unico nella GDT ed ha TI = 0 e Index = 0. Molta documentazione asserisce che questa entry debba essere 0. Anche se Intel è un po'ambigua su questo soggetto, non ha mai detto per cosa NON può essere usato. Intel asserisce che l'entry 0 non è mai referenziata dal processore.
Poichè il processore non referenzia mai il NULL descriptor, questo implica che i dati memorizzati in quel posto possono essere usati per qualunque scopo. Il mio uso preferito del NULL descriptor è come puntatore alla GDT stessa! L'istruzione LGDT necessita di un puntatore a 6 byte alla GDT e il NULL descriptor ha 8 byte che non vengono acceduti dalla CPU, rendendolo un candidato ideale per questo scopo (Per voi scettici, ho fatto questo per una decina d'anni). Il protocollo normale usato nell'indirizzamento della GDT è il seguente:
GDT_PTR DW GDT_LENGTH-1
DD PHYSICAL_GDT_ADDRESS
Poi
nel segmento codice
LGDT GDT_PTR
Usando il NULL descriptor come puntatore alla GDT semplifica
il segmento data e la concettualizzazione della GDT come segue:
+-----------------+
| |
V | Offset
+------------------------+ |
GDT | Pointer to the GDT | ---+ 00h
+------------------------+
| | 08h
+------------------------+
| ... ... ... ... |
Quindi nel segmento codice LGDT GDT
La variabile GDT_PTR non è più necessaria visto che il NULL descriptor è usato al suo posto. (C'è anche un sorgente che usa questa variante http://www.x86.org/ftp/dloads/int09.zip, guardate soprattuto la macro.
Ok Wolf, ci hai tenuto banco per tutte queste pagine parlando di Protected Mode, Protected Mode, e Protected Mode ma come si fa ad "attivare" questa protected mode?
Boni, ora non voglio sconfinare nelle terre dell' OS Dev perchè di cose da dire ce ne sarebbero veramente TANTE, tanto è tutta roba che mi sto pappando anche io, per cui tra un po' rilascerò altri articoli, anche perchè per rispondere a questa domanda ad esempio, dovremo parlare del boot, del bootloader...cioe' incollarvi un pezzo di codice che ho a portata di clic non mi costa niente, però mi sembra inutile... Intanto dovete/dobbiamo digerire tutta sta roba, aspe', e non sono sceso in dettagli, ho saltato del tutto la parte sui debug register e Control Register (e la pmode si attiva proprio mediante il CR0)...insomma, abbiate fede, non abbandonerò i miei fedeli :D ROTFL Poi mi garbava anche di scrivermi dei dumper personali...vero evil, io e te avevamo anche cominciato, vero signorino? :P mannaggia a te, mannaggia......
| Note finali |
Saluto Ntoskrnl (ovviamente :P grazie davvero per le tue note e per aver corretto qualche mio strafalcione, attualmente 02/08/2004 in Norvegia, sulle isole Lofoten, mi ha appena mandato sms), albe, Quequero, andreageddon, evilcry (...), Ironspark, i satelliti di marte :D , ZaiRoN, MrCode, la nostra Giulia (giù io aspetto sempre il tuo Tasm vs Masm :P), e tutti quelli che hanno e hanno avuto la sfortuna di conoscermi :P
| Disclaimer |
Sono contento di averlo fatto, ho imparato molto. Come sono andato?