Let's talk about Masm 6.1x
* Supporto completo Win32. Un'applicazione scritta con masm è una vera applicazione win32 console e supporta nomi lunghi per i src, file oggetto...
* Supporta sia di Intel OMF ("old") che COFF - Common Object File Format - (Win32)
* Controllo dei parametri in fase di assemblamento. Generazione di nome decorati che permettono un controllo in fase di linking del numero di parametri passati ad una funzione (ad esempio nella definizione di PROC e PROTO) e questo può essere usato dalle win32 import libraries per evitare crash in caso venissero passati parametri errati
In caso di errore masm genera il postfix "@" sbagliato e il link fallisce con un riferimento indefinito. E questo è sempre meglio che ritrovarsi ad avere a che fare con errori a run time impredicibili.
* Supporto TYPEDEF
* Supporto della direttiva INCLUDELIB per semplificare il processo di linking e permettere l'invocazione automatica delle librerie importate dal linker
* INVOKE - Masm provvede questa macro per gestire molte dei dettagli importanti per le chiamate di procedure, come il pushing dei parametri nel rispetto della calling convention.
* La vecchia definizione dei dati (DB, DW, DD) è stata estesa con tipi nuovi e più precisi (i vecchi sono cmq sempre validi):
BYTE, SBYTE, WORD, SWORD, DWORD, SDWORD, FWORD, QWORD, TBYTE, REAL4, REAL8, REAL10.
Nota su INVOKE:
Esiste una piccola limitazione sull'uso di questa direttiva (in ML), quella che all'epoca venne definita "The infamous 512 bytes buffer":
Il suo input buffer (parsing) aka "logical line" è solo di 512 byte. Questo è documentato pure nel Prog.Guide Chapter 1/ Language Components of MASM/ Statements", page 22. Diciamo che dobbiamo chiamare una funzione. Ma quando una INVOKE di Win32 viene fatta con una lunga lista di parametri, si potrebbe voler scrivere (e commentare) in un modo simile:
INVOKE CreateProcess,
OFFSET lpApplicationName, ;=> to EXE name
OFFSET lpCommandLine, ;=> to command line string
OFFSET lpProcessAttributes, ;=> to process sec attribs
OFFSET lpThreadAttributes, ;=> to thread sec attribs
bInheritHandles, ;handle inheritance flag
dwCreationFlags, ;creation flags
OFFSET lpEnvironment, ;=> to new env block
OFFSET lpCurrentDirectory, ;=> to current dir name
OFFSET lpStartupInfo, ;=> to STARTUPINFO
OFFSET lpProcessInformation ;=> to PROCESS_INFORMATION
Bene, scordatelo. I commenti contano nei 512 byte, così che la
"logical line" (che non usa TAB ma spazi) non entra nel buffer di 512 byte.
Masm lo segnerà come errore. Per cui spesso ci si potrebbe trovare a rimuovere
commenti e spazi, packare molti parametri per linea. Non si supera l'ostacolo
con il carattere di continuazione \ o altri barbatrucchi (mamma miiiaaa che
figurone che farete in classe... :P iihhihi). Beh, non so, non mi sono ancora
documentato, tuttavia ha senso pensare che se siamo arrivati a
Masm8...l'avranno sistemata sta cosa...boh :P Sull'organizzazione dei segmenti
Allora, nella famigghia dei processori basati su 8086 il termine segmento ha 2 significati:
- Un blocco di memoria di una discreta grandezza chiamato "segmento fisico" (ripeto, il numero di byte in un segmento di memoria fisico è 64K per processori a 16 bit, meh, non ve lo dico più)
- Un blocco di memoria di grandezza variabile chiamato "segmento logico" occupato dal codice o dai dati di un programma.
Segmenti di memoria fisica
Come spiegato prima, un segmento fisico può iniziare solo a una locazione di memoria il cui indirizzo sia divisibile per 16, compreso l'indirizzo 0. Intel chiama queste locazioni "Paragrafi" per cui si può riconoscere facilmente la locazione di un paragrafo dato che il suo indirizzo termina sempre con 0 (1000h o 2EA70h).
Segmenti logici
I segmenti logici contengono I 3 componenti di un programma: codice, dati e stack. MASM si preoccupa di organizzare le 3 parti per noi così che occupano segmenti fisici di memoria. I registri di segmento CS, DS e SS contengono gli indirizzi dei segmenti fisici dove risiedono i segmenti logici Possiamo definire i nostri cari segmenti in 2 modi: con le "direttive di segmento semplificate" o con le "direttive estese", che possiamo usare anche insieme nello stesso programma. Dato che le hanno chiamate "semplificate", queste direttive nascondono molti dei dettagli delle definizioni dei segmenti e si occupano di generare il codice opportuno per specificare gli attributi dei segmenti e ordinarli (si, è possibile anche definire un ordine). Le direttive complete, "full", richiedono una sintassi più complicata (che sfiga eh? ;D) ma forniscono più controllo su come l'assemblatore genera i segmenti.
Prima di andare oltre: near e far
Ma in questo contesto che significa parlare di dati vicini, lontani? a/da cosa? Gli indirizzi che hanno un nome di segmento implicito o registri di segmento associati con loro vengono chiamati near address. Gli indirizzi che hanno un esplicito segmento associato con loro vengono chiamati far address. L'assemblatore gestisce il codice near o far automaticamente mentre bisogna specificarli come gestire i dati near o far. Il modello di segmento microsoft mette tutti i dati near e lo stack in un gruppo chiamato DGROUP (Andreageddon non lo sapeeevaaaa, Andreageddon non lo sapeeevaaa :P). Il codice near viene messo in un segmento chiamato _TEXT. Il codice o i dati far di un modulo vengono messi in un segmento separato. L'assemblatore non è in grado di determinare gli indirizzi per alcuni componenti del programma e questi vengono detti rilocabili. L'assemblatore genera un record e il linker provvede l'indirizzo una volta che ha ottenuto l'indirizzo di tutti i segmenti.
Ad esempio, dati che si trovano nello stesso segmento (diciamo DS, default) vengono 'raggiunti' indicando solo l'offset per cui si dice che sono near, se invece dovessimo avere un programma con una vagonata di dati che occupano anche un altro segmento (diciamo ES), dovremo specificare in qualche modo anche il segmento in cui si trovano determinati dati per cui si dice che sono far.
Codice near
I trasferimenti di controllo all'interno di codice near non richiedono cambiamenti ai registri di segmento (perchè sono sempre nello stesso, sono "vicini", "in zona" :D) e il processore gestisce automaticamente i cambiamenti dell'offset nel registro IP quando il flusso del programma viene modificato da istruzioni come JMP, CALL e RET.
call nearproc ;<- cambia l'offset del codice
Questa chiamata cambia ovviamente il registro IP in modo che questo punti a un nuovo indirizzo ma lascia inalterato il segmento (ricordate segmento:offset?). Quando la procedura ritorna, il processore resetta IP all'offset della successiva istruzione alla call
Codice far
In questo caso il processore gestisce i cambiamenti ai registri di segmento.
call farproc ; <-cambia segmento e offset
muove automaticamente in CS e IP il segmento e l'offset della procedura farproc ove essa risiede (capito il senso di vicino e lontano?). Quando poi la call termina e la procedura ritorna il processore setta CS al valore originale e IP punta all'istuzione successiva alla call.
Dati near
Un programma accede ai dati near direttamente perchè un registro di segmento mantiene già il segmento corretto per il dato. Spesso il termine near è usato in riferimento ai dati nel gruppo DGROUP. Dopo la prima inizializzazione di DS e SS, questi registri puntano normalmente a DGROUP. Se durante l'esecuzione del programma vengono modificati, perdendo così il riferimento, questi registri vanno ripristinati al loro valore prima di poter riferirsi a qualsiasi elemento nel DGROUP (causando potenzialmente errori psichedelici :P) Il processore assume che tutti i riferimenti di memoria siano relativi al segmento nel registro DS, con l'eccezione dei riferimenti che usano BP o SP. Il processore associa questi registri con SS. (comportamento che si può comunque "bypassare" o per meglio dire si può fare "override"..però ve lo spiego un'altra volta) Il seguente esempio dimostra come il processore acceda sia ai segmenti DS che SS a seconda di dove l'operatore puntatore contenga BP o SP. La distinzione perde significato quando DS e SS sono uguali.
near WORD 0 ... mov ax,near ; <- legge da DS:[near] mov di,[bx] ; <- legge da DS:[BX] mov [di],cx ; <- scrive in DS:[DI] mov [bp+6], ax ; <- scrive in SS:[BP+6] mov bx,[BP] ; <-legge da SS:[BP]Dati far
Per leggere o modificare un dato far, un registro di segmento deve puntare al segmento che contiene il dato. Questo richiede 2 passi. Primo, caricare il segmeno (normalmente ES o DS) con il valore corretto, e poi (opzionalmente) settare una direttiva ASSUME (che vedremo dopo nei dettagli) al segmento dell'indirizzo. Un paio di esempi, che è meglio.
Un metodo comune per accedere ai dati far è inizializzare ES:
;primo metodo
mov ax, SEG farvar
mov es, ax ; <- carica in ES il segmento dell'indirizzo far
mov ax, es:farvar ; <- fornisce un esplicito segment override sull'indirizzamento
; mette in ax il dato contenuto (segmento:offset) nel segmento ES all'offset di farvar quindi
(Restrizione Intel, non si
può passare il SEG direttamente a un registro di segmento)
;secondo metodo
mov ax, SEG farvar
mov es, ax
ASSUME ES:SEG farvar ; <- dice all'assemblatore che da ora ES contiene l'indirizzo
del segmento farvar
mov ax,farvar
Se un'istruzione
necessita di sostituire un segmento, il codice risultante sarà un po'più
grande visto che il passaggio deve essere codificato nel prog, cmq il codice
risultante potrebbe ancora esser più piccolo del codice generato per fare
caricamenti multipli del segmento default. Se un programma usa ES per accedere
ai dati far non ha bisogno di ripristinare ES quando ha finito (a meno che il
prog non usi il modello FLAT). Cmq alcuni compilatori richiedono di
ripristinare ES. Per accedere ai dati far, settare prima DS al segmento far e
poi ripristinare il valore originale. Altro esempio:
push ds ; <- salva il
segmento dati
mov ax, SEG fararray
mov ds, ax
ASSUME ds: SEG
fararray
mov ax, fararray[0]
...
pop ds ; <-
ripristina il segmento
ASSUME ds: @data ; <-e
l'assunzione default
(beh ASSUME è solo una macro, a livello di asm diventa
la stessa cosa che il primo codice, ndnt)
Uso
delle definizioni estese dei
segmenti
"Ehm...ragazzi,
prendetela per bona sta parte, dovete fidarvi..." ihihiihihi E'un po'dura
questa parte, ma come si fa a usare le direttive semplificate...se non si sa
COSA semplificano? :> Un segmento definito inizia con la direttiva SEGMENT
e termina con la direttiva ENDS (END Segment immagino :P):
Agevoliamo
un esempio prima di passare alla sintassi:
STACK SEGMENT PARA STACK 'STACK'
DB 200h DUP (?)
STACK ENDS
DATA SEGMENT WORD 'DATA'
msg DB 'Lonely Wolf',13,10,'$'
DATA ENDS
CODE SEGMENT WORD 'CODE'
ASSUME cs:CODE, ds:DATA
Start:
mov ax,DATA
mov ds,ax ; <- carica in DS il segmento dati.
mov dx,OFFSET msg ; <- DS:DX punta così al messaggio (perchè DS è il segmento dati, msg è un dato...per cui ;D)
mov ah,9
int 21h
mov ah,4Ch
int 21h
CODE ENDS
END Start(devo confessarvi che questo esempio però l'ho preso
dal librozzo sul Tasm, a memoria non me lo ricordavo, e dando un'occhiata sta
faccenda non la spiega così dettagliatamente come il manuale del masm) name SEGMENT [align] [READONLY] [combine] [use] ['class'] dichiarazioni name ENDS
name ovviamente definisce il nome del segmento. Il linker può anche combinare segmenti con nomi identici da moduli differenti se però il valore di combine non è PRIVATE. Le seguenti opzioni per la direttiva SEGMENT danno al linker e all'assemblatore istruzioni su come settare e combinare i segmenti: (ulteriormente commentati tra poco)
align Definisce il limite di memoria sul quale inizia un nuovo segmento
READONLY Dice all'assemblatore di riportare un errore se qualsiasi istruzione cerca di modificare qualcosa
nel segmento READONLY
combine Determina come il linker dovrà combinare i segmenti da moduli diversi quando crea l'eseguibile.
use Determina la grandezza di un segmento. USE16 indica che gli offset nei segmenti sono su 16bit,
mentre USE32...(questo funge solo 386/486)
class Provvede un nome di classe per il segmento. Il linker automaticamente raggruppa i segmenti
della stessa classe in memoria
Ovviamente non si possono cambiare le proprietà di un segmento una volta definite
Allineamento dei Segmenti (align)
Questo tipo opzionale nella direttiva SEGMENT definisce il range di indirizzi di memoria dal quale un indirizzo di inizio per il segmento verrà selezionato (Giobe dice: "...indica all'assemblatore a quale indirizzo offset dovrà essere collocato il primo bytes del segmento a cui la direttiva si riferisce; questa indicazione verrà codificata dal linker dentro l'header del file exe prodotto per poi passarla al loader del Dos..") e può essere uno dei seguenti:
BYTE L'indirizzo del prossimo byte disponibile/primo indirizzo libero
WORD L'indirizzo della prossima parola disponibile/a partire da un indirizzo multiplo di 2 con il bit meno
significativo a 0
La distanza dagli altri eventuali segmenti è al max 2 byte
DWORD L'indirizzo della prossima DWORD disponibile
PARA L'indirizzo del prossimo paragrafo disponibile (16 byte per paragrafo). DEFAULT
A partire da un indirizzo multiplo di 16, cioè con il nibble meno significativo a 0, quindi distanza max
altri eventuali
segmenti = 16 byte
PAGE L'indirizzo della prossima pagina disponibile (256 byte per pagina)/a partire da un indirizzo
multiplo di 256, cioè con i 2 bytes meno significativi a 00h; la distanza da eventuali
altri segmenti è al max 256 byte
Il linker usa le informazioni di allineamento per determinare l'indirizzo di partenza relativo per ogni segmento e il sistema operativo calcola l'indirizzo di partenza corrente quando il programma viene caricato.
Rendere i segmenti di sola lettura (READONLY)
Questo attributo (come dice il nome :P) è utile quando devi creare un segmento codice in sola lettura per protected mode ad esempio e per citare alla lettera il manuale "It protects against illegal self-modifying code". L'assemblatore genererà quindi un errore quando si cerca di scrivere su uno di codesti segmenti.
Combinazione di segmenti
(combine)
Questo tipo opzionale
determina come il linker deve comportarsi quando trova in moduli diversi
segmenti aventi lo stesso nome. combine controllo il comportamento del linker
non dell'assemblatore.
PRIVATE NON combina i segmenti anche se hanno lo stesso nome. DEFAULT
PUBLIC Concatena tutti i segmenti aventi lo stesso nome per formare un unico e contiguo segmento
STACK Concatena tutti i segmenti aventi lo stesso nome e fa si che il sistema operativo setti SS:00 sul fondo
e SS:SP che punta alla cima al segmento risultante. L'inizializzazione dei dati è inaffidabile come vediamo dopo
COMMON Sovrappone i segmenti. La lunghezza dell'area risultante è la lunghezza del più grande dei segmenti combinati.
L'inizializzazione dei dati è inaffidabile come vediamo dopo
MEMORY Usato come sinonimo di PUBLIC (mmmahhh)
AT address Prende address come locazione del segmento. Un segmeno AT non può contenere alcun codice o dati inizializzatoma
è utile per definire strutture o variabili che corrispondono a specificare locazioni di memoria far come uno
screen buffer. Non si usa in protected mode.
Non mettete dati inizializzati nei segmenti STACK e COMMON. Con questi tipi di combine, il linker sovrascrive i dati inizializzati di ogni modulo all'inizio del segmento. L'ultimo modulo contenente dati inizializzati scrive sugli altri degli altri moduli. Normalmente si deve provvedere almeno un segmento stack (che abbia il tipo combine STACK) in un programma. Se nessun segmento stack viene dichiarato, LINK visualizza un messaggio di errore che puoi ignorare se hai una ragione specifica per non dichiarare un segmento stack, ad esempio perchè si potrebbe non volere un segmento stack separato in un file.com
Ordinamento dei segmenti (class)
Il tipo opzionale class aiuta a controllare l'ordinamento dei segmenti. 2 segmenti con lo stesso nome non sono combinati se la loro classe è diversa. Il linker dispone i segmenti così che tutti i segmenti identificati con un dato tipo class siano consecutivi nel file exe. Comunque, all'interno di una classe il linker dispone i segmenti nell'ordine incontrato. le direttive .ALPHA (sta per alphabetic).SEQ (default. dispone i segmenti nell'ordine in cui gli diciamo) .DOSSEG (ordine dei segmenti convenzionale per MS-DOS, ovvero 1.Segmento codice 2.Segmento Dati in questo ordine: a) Segmenti che non sono nella classe BSS (che se non lo sapete, dopo vi dico cosa è, però solo se fate i bravi :P ihih) o STACK b) Segmenti della classe BSS c) Segmenti della classe STACK) determinano questo ordine nel file OBJ. Il metodo più comune è di specificare un tipo class per piazzare tutti i segmenti codice per primi nel file exe. Di solito questo ordinamento può essere ignorato. Comunque potrebbe essere importante se si volesse che un segmento appaia all'inizio o alla fine di un programma. Come appena detto, per i file com, il segmento codice deve apparire primo nel file eseguibile visto che l'esecuzione inizia all'indirizzo 100h.
Oh, ci siete sempre? :D
Ci siamo quasi, ora facciamo ASSUME, poi un po'di direttive semplificate (eheh io anche se il prof non le aveva mai spiegate usavo le direttive semplificate, nei compiti in classe era tattico: 1.le usavo solo io 2.avevo più tempo a disposizione ;D)
La direttiva ASSUME per i registri di segmento
Molte delle istruzioni assembler ASSUMONO, prendono per bono come si dice qui :p che ci sia un certo segmento di default. Ad esempio, JMP ASSUME che il segmento associato sia con il CS, PUSH e POP ASSUMONO il registro CS e le istruzioni MOV ASSUMONO che il segmento associato sia il DS. Come è logico pensare, Quando l'assemblatore ha bisogna di referenziare un oggetto deve sapere QUALE segmento CONTIENE l'indirizzo. Chi gli da questa informazione? La direttiva ASSUME. Un po' di sintassi anche qui:
ASSUME segregister:seglocation [, segregister:seglocation] ASSUME dataregister:qualifiedtype [, dataregister:qualifiedtype] ASSUME register:ERROR [,register:ERROR] ASSUME [register:] NOTHING [, register:NOTHING] ASSUME register:FLAT [, register:FLAT]
seglocation deve essere il nome del segmento o di un gruppo associato con il segregister. Le altre istruzioni che assumono un registro di default per referenziare le label o le variabili automaticamente assume che se il segmento di default è segregister, la label o la variabile è nella seglocation. Segregister può essere CS,DS,ES,SS (FS e GS per 386/486) mentre seglocation può essere:
-Il nome del segmento definito nel nostro sorgente con la direttiva SEGMENT
-Il nome di un gruppo definito con la direttiva GROUP
-La parola chiave NOTHING, ERROR o FLAT
-Una espressione SEG
(l'operatore SEG ritorna l'indirizzo del segmento di una locazione di memoria:
mov ax,SEG farvar ; <- Load Segment Address
mov es,ax
)
Una piccola nota che ho trovato su FS: il registro FS contiene in ogni
momento un selettore valido, ed è stato documentato da Pietrek in [Pietrek
95.01]. Questo selettore in FS punta a un TIB (Thread Information Block) che
contiene svariate info sugli elementi inerenti thread. I contenuti di un TIB
sono usati da molte Win32 syscall.
La parola chiave NOTHING cancella
l'assunzione corrente, o meglio, ASSUME NOTHING cancella ogni assunzione sui
registri fatta in una precedente ASSUME qualcosa.. Di solito una singola
dichiarazione ASSUME definisce tutti i 4 registri di segmento all'inizio del
file sorgente, anche se comunque si può usare una direttiva ASSUME in
qualsiasi punto del programma. L'uso della direttiva ASSUME per cambiare una
assunzione su un segmento è spesso equivalente a cambiare l'assunzione con
l'operatore di segment override : che eventualmente, se questo tute vi è
piaciuto possiamo vedere la prossima volta, per i masm evangelist :D heheh
Comunque, un programma deve caricare esplicitamente un registro di segmento
con un certo indirizzo di segmento prima di poter accedere ai dati all'interno
di tale segmento (ehbbeh). ASSUME dice semplicemente all'assemblatore di
assumere che tale registro è stato correttamente inizializzato.
NOTA:
Masm 6.1 assegna AUTOMATICAMENTE al registro CS l'indirizzo
del segmento codice corrente del programma, così che non c'è bisogno di
includere nel nostro programma ASSUME CS:
_MYCODE
NOTA2:
Questa direttiva ASSUME riguarda solo le
assunzioni fatte in fase di assemblaggio, non in runtime.
Definizione
di gruppi di segmento
Un gruppo è una
collezione di segmenti che non superano i 64K in modalità 16bit. Un programma
indirizza un codice o i vari elementi dei dati nel gruppo relativo all'inizio
del gruppo. Un gruppo ti permette di sviluppare segmenti logici separati per
tipi di dati diversi a poi combinarli in un unico segmento (gruppo) per tutti
i dati. L'uso di un gruppo evita di dover continuamente ricaricare registri di
segmento per accedere a diversi segmenti e di conseguenza il programma userà
poche istruzioni e sarà anche un pochino più veloce.
L'esempio più comune
di un gruppo è quello speciale per i dati near chiamato DGROUP. Nel modello
dei segmenti Micro$oft, molti segmenti (_DATA, _BSS, CONST, STACK) sono
combinati in questo DGROUP.
Siccome non lo sapevo e mi sono documentato,
per la cronaca
BSS (Block Started by Symbol deriva da un vecchio operatore asm) è quella
regione di memoria che contiene le variabili globali (non inizializzate) e
statiche mentre come sapete bene lo heap viene usato per l'allocazione
dinamica della memoria.
Figoooo!!, guardate questo schemettino che ho
trovato girottolando sulla memoria (nelle SPARC ma la zuppa è
quella):
| . . . |
+-------+ -. int x = 1; /* x placed in data */
| text | \ int y; /* y in placed bss */
|-------| | program's int main(){
| data | | layout in int z; /* z alloc. on stack */
|-------| | memory ...
| bss | | y = 2; /* code put in text */
|-------| | ...
| heap | | return 0; /* retval in reg %o0 */
|---|---| | }
| . V . | |
| . . . | | a dynamically allocated variable will
| . ^ . | | placed in the heap
|---|---| |
| stack | / a local variable declared with the
+-------+ -' keyword "static" in C will be placed
| | in the stack
| . . . |
I linguaggi di alto livello M$ (qua sta scritto così) piazzano
tutti i segmenti dati near in questo DGROUP. La direttiva .MODEL definisce
automaticamente il DGROUP e il registro DS normalmente punta all'inizio del
gruppo fornendo un accesso relativamente veloce a tutti i dati nel DGROUP.
name GROUP segment [, segment]
dove name è ovviamente la label scelta del gruppo e può riferirsi anche a un gruppo precedentemente definito. Questa funzione ci lascia aggiungere segmenti al gruppo uno alla volta. Ad esempio, se MYGROUP era stato precedentemente definito per includere ASEG e BSEG allora
MYGROUP GROUP CSEG
aggiunge semplicemente CSEG e gli altri due NON vengono rimossi. Ogni segment può essere qualsiasi nome di segmento valido con un'unica restrizione: un segmento non può appartenere a più di un gruppo. Questa direttiva non riguarda l'ordine con il quale i segmenti di un gruppo vengono caricati.
Uso delle direttive semplificate
Che sudata eh? Ci siete fin qui? Come ci ispira il nome, con queste direttive ci dovremmo risparmiare l'ingrato compito di definire nei dettagli segmenti, ordinamenti e amenità simili...vediamo, vediamo. Le direttive semplificate sono
.MODEL
.CODE
.CONST
.DATA
.DATA?
.FARDATA
.FARDATA?
.CODE
.STACK
.STARTUP
.EXIT
L'avevo dato per scontato, cmq per la cronaca, un programma Masm consiste in moduli fatti di segmenti. Ogni programma scritto solo in Masm ha un modulo principale (main) dove inizia l'esecuzione del programma. Questo main module può contenere codice, dati, o segmenti stack definiti con queste benedette direttive semplificate. Qualsiasi modulo aggiuntivo dovrà contenere solo il segmento codice e data. Comunque, attenzione, ogni modulo che usa queste direttive semplificate dovrà sempre cominciare con la direttiva .MODEL. Vediamo un esempio che mostra la struttura di un modulo principale che usa queste direttive. Usa il processore default (8086) e la distanza di stack default (NEARSTACK). Come si diceva prima, eventuali moduli linkati useranno solo le direttive .MODEL .CODE .DATA e .END per terminare, ovviamente. (lo so, avrò detto ovviamente 10000 volte, è colpa di Ntoskrnl, a forza di andare a giro con lui l'ho appreso per osmosi :D rotfl)
.MODEL small, c .STACK ; <- Usa per default 1Kb di stack, altrimenti si specifica quanto ci serve es. .STACK 2048 ovvero 2Kb .DATA ; <- Inizio data segment <- ;inserire qui le varie dichiarazioni, variabili ecc.. .CODE ; <- Inizio del segmento codice .STARTUP ; <- Genera codice di avvio (visto ganzo lo fa lui?) ; <- le istruzioni del vostro programma .EXIT ; <- Genera codice di uscita END ; <- Deve stare alla fine di ogni modulo
Le direttive .DATA e .CODE non hanno bisogno di una dichiarazione separata per indicare il loro termine
Definizione degli attributi base di .MODEL
questa direttiva è importantissima poichè riguarda l'intero modulo: il modello della memoria, default calling e naming conventions, sistema operativo e tipo di stack (per ulteriori info guarda sotto "Calling e naming convention: queste sconosciute").
Quindi, in cima in cima al nostro programma ci sarà
.MODEL memorymodel [, modeloptions]memorymodel è obbligatorio e gli eventuali modeloptions devono essere separati da virgola (o eventualmente passati da riga di comando con ml). Vediamo nei dettagli le varie opzioni
Memory model TINY, SMALL, COMPACT, MEDIUM, LARGE, HUGE, FLAT.
Determina la grandezza del codice e dei data pointers.
Language C, BASIC, FORTRAN, PASCAL, SYSCALL, STDCALL.
Stabilisce le calling e naming conventions per le procedure e i simboli pubblici (approfondiamo dopo se
sopravvivo a questo tute :P)
Stack distance NEARSTACK, FARSTACK.
Specificando NEARSTACK il segmento stack viene raggruppato in un singolo segmento fisico (DGROUP)
con i dati e si assume che SS sia uguale a DS. Specificando FARSTACK il segmento non viene
raggruppato in DGROUP ed evidentemente SS non sarà uguale a DS.
Si possono usare delle 'combo' come le chiamo io certe cose :D ovvero
.MODEL small .MODEL large, c, farstack Definizione dei modelli di memoria Ma guarda un po'che gatta da pelare che mi sono procurato ;) Vai col tabellozzo, prego la regia... (sul manuale del masm è + dettagliata sta tabella, io ho potato alcuni campi) Mem.Model Default Code Default Data ============================================== Tiny Near Near Small Near Near Medium Far Near Compact Near Far Large Far Far Huge Far Far Flat Near Near ==============================================E' cosa buona e giusta scegliere il modello di memoria più piccolo che contiene i nostri dati e codice.
In breve
Small, Medium, Compact, Large ed Huge
Il modello di memoria Small supporta un segmento dati e un segmento codice. Il modello Large supporta segmenti codice e dati multipli, mentre Medium supporta segmenti codice multipli ma segmento dati singolo e Compact segmento dati multiplo e segmento codice singolo. E cmq sia, possiamo fare l'override del default, ad esempio possiamo mettere elementi "larghi/lontani"(far) nel modello Small
Tiny
Funziona solo sotto MS-DOS, piazza il segmento codice e dati in un singolo segmento e cmq la grandezza totale del programma non può occupare più di 64Kb. Di default codice e dati statici sono near e non si può fare l'override di questa cosa anche se è possibile allocare dati far dinamicamente al run time usando servizi MS-DOS per allocazione. Tiny produce file .COM e invia al linker l'argomento /TINY
Flat
Dal Manuale Intel: Usando questo modello, un programma vede la memoria come un singolo e continuo spazio di indirizzi chiamato linear address space. Il modello base di flat nasconde i meccanismi di segmentazione dell'architettura anche al programmatore applicativo. Per implementare un modello di memoria flat di base devono essere creati almeno 2 segment descriptor, uno per referenziare un segmento codice, l'altro per un segmento dati. Entrambi questi segmenti comunque, sono mappati sull'intero Linear Address Space, ovvero entrambi i segmenti hanno lo stesso valore di base address (cioè 0) e lo stesso valore di limit di 4 Gb. Questo modello di memoria NON segmentato è disponibile su sistemi operativi a 32bit, diciamo, simile al modello Tiny per il fatto che tutto il codice e i dati stanno in un unico segmento di 32 bit. Questo spazio di indirizzi (fisico) non segmentato può essere mappato come memoria read-only, read-write e memory mapped I/O. Sempre da Manuale Intel: L'architettura IA-32 supporta anche un estensione dello spazio di indirizzi fisico a 236 (64 Gb) con un indirizzo fisico massimo pari a FFFFFFFFF...(Per ulteriori informazioni sapete dove cercare ;P) (sarebbe il PAE a cui ti riferisci - lo so nt, Physical Address Extension ma per oggi non ne parliamo che se no non ne esco più -, per completezza ti ho trovato un piccolo riferimento all'argomento: http://www.microsoft.com/whdc/hwdev/platform/server/pae/default.mspx, ndnt) Per usare il modello Flat prima di usare la direttiva .MODEL bisogna esplicitare .386 o .486 (indovinate un po', indica la modalità del processore che intendiamo usare nel nostro programma, è il set di direttive per selezionare il processore e il coprocessore). Il sistema operativo automaticamente inizializza i registri di segmento al momento del caricamento. CS, DS, ES ed SS occupano tutti il supergruppo FLAT.
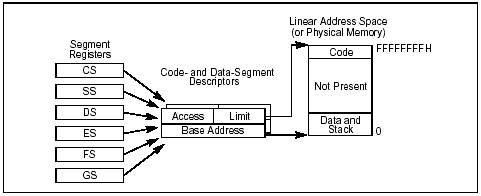
Tutti i registri di segmento contengono descrittori che mappano l'intero spazio di indirizzi logico che le nostre applicazioni vedono. NOTA: Intel specifica che si possono implementare 2 tipi diversi di modello flat: Base (quello che abbiamo appena visto), Protetto (differisce dal precedente solo per i segment limits che sono settati per includere solo il range di indirizzi per il quale la memoria fisica esiste attualmente fornendo così un livello minimo di protezione) e MultiSegmento (fornisce un livello di protezione ancora più elevato facendo si che ogni programma (o task) abbia una propria tabella di segmenti descrittori e i propri segmenti che possono anche essere completamente privati)...
ATTENZIONE!
Guardate un po' cosa ho trovato riguardo il modello flat...
"...The first one is the "flat model" dogma: "Win32 uses the flat model, and this This is simply not true. model precludes the use of segmentation..."
L'autore di questa Win32Faq, ho cercato la sua firma nel txt ma non so chi sia, dice che non è affatto vero che nel modello FLAT non si possano usare i registri di segmento, e quasi sarcasticamente dice che There is no such thing in the Intel CPU as a "flat model bit", è soltanto una convenzione. L'uso di questo modello non eredita alcuna limitazione-CPU per un programatore che occasionalmente volesse usare i registri di segmento. Strano, in un file hlp del masm 8 leggo:
"...Differing from earlier 16 bit code that used combined segment and offset addressing with a 64k segment limit, FLAT memory model works only in offsets and has a range of 4 gigabytes. This makes assembler easier to write and the code is generally a lot faster. All segment registers are automatically set to the same value with this memory model and this means that segment / offset addressing must NOT be used in 32 bit programs that run in 32 bit Windows.
???
Prosegue " the best evidence is that Microsoft themselves use segmentation in the Win32 world: in any Win32 thread, the FS register always contains a special descriptor, that doesn't follow the flat model rules, and is used to access the TID (Thread Information Block, see [Pietrek 95.01]). The lack of access to segmentation from Ring 3 code only comes from an OS design decision...The second explanation Microsoft commonly gives about the lack of access to segmentation from Ring 3 code is the need for portability, and the lack of hardware mechanisms to implement segmentation on non-Intel platforms. As we already mentioned, this looks to us as a very moot point, as " e fa un elenco di motivazioni per confutare l'affermazione di M$ e le sue proposte per implementare LDT a quanto ho capito. Boh, non so se tutto questo sia roba vecchia, cmq in caso vi giro questo file.
Specificare un processore e un coprocessore
Masm supporta un set di direttive per selezionare processori e coprocessori. Naturalmente, una volta che si sceglie un processore dobbiamo usare solo il set di istruzioni per quel processore, è evidente. Il default è 8086, per cui se va bene così non importa esplicitarlo in alcun modo. La selezione avviene specificando in cima al codice del programma una delle direttive .186 .286 .386 .486 .586 Le direttive .286P .386P .486P abilitano quelle istruzioni disponibili solo a un livello più alto di priviliegio in aggiunta al normale set di istruzioni per il processore dato. Per selezionare un coprocessore matematico usa le direttive .8087 (default) .287 .387 e .NO87 (quest'ultima disattiva ogni istruzione legata al coprocessore. Attenzione: dal processore 486 registri e istruzioni del coprocessore sono built-in,per cui in tal caso non serve specificare. >
Settare la distanza dello Stack
Come abbiamo detto poco fa, la parola chiave NEARSTACK (conveniente per la maggioranza dei programmi) piazza il segmento Stack nel DGROUP con il segmento data. La direttiva .STARTUP poi genera il codice per aggiustare SS:SP così che SS abbia lo stesso indirizzo del DS. Se omettiamo .STARTUP dovremo farla a manina questa cosa. In questo caso si potrà usare quindi DS per accedere agli elementi nello stack (inclusi di conseguenza parametri e variabili locali) a SS per accedere ai dati near. FARSTACK in pratica fa creare un segmento stack a se' stante . Barbanera consiglia...ehm, Masm consiglia di usare FARSTACK per programmi residenti in memoria e DLL. Il simbolo predefinito @stack ci dice se la locazione dello stack è il DGROUP (near) o STACK.
Creazione di uno Stack
Cmq, lo stack (pila - LIFO dai su che lo sapete) è un'area di memoria usata per il pushing e popping dei registri e per memorizzare l'indirizzo di ritorno quando viene chiamata una subroutine, per le variabili locali e il passaggio dei parametri. Come detto sopra, se uno volesse uno stack più grande del default di 1Kb, lo specifica direttamente con .STACK size (Es .STACK 2048). Se volete approfondire, abbiamo ad esempio itassembly.cjb.net o bigspider.cjb.net, abbiamo sempre L'architettura x86, struttura generale del solito Andreageddon, oppure vi consiglio di leggervi un vecchio(?) articolo apparso su Assembly Programming Journal Vol 1 n.4 - Stack Frames and High-Level Calls niente meno che di mammon_ Ho quasi finito, pazienza, su non piangete :)
Creazione di un segmento Dati
I programmi possono contenere sia dati far che near. E'buona norma che i dati usati più di frequente si trovino nell'area near, dove l'accesso è anche più veloce. Quest'area può diventare affollata, cmq, perchè in un sistema operativo a 16bit l'ammontare totale di tutti i dati near in tutti i moduli non può eccedere 64Kb
Le direttive .DATA .DATA? .FARDATA .FARDATA? creano segmenti dati e si può accedere ai vari segmenti all'interno del DGROUP senza dover ricaricare i registri di segmento e queste direttive possono impedire che le istruzioni appaiano nel segmento dati assumendo CS come ERROR (poi si spiega anche questo e cmq con le direttive estese si usa ASSUME CS:ERROR).
Segmenti dati near
La direttiva .DATA crea un segmento dati near (max 64Kb). Quando si usa .MODEL l'assemblatore definisce automaticamente sto benedetto DGROUP per i nostri segmenti dati che sono normalmente acceduti attraverso DS o SS. (la direttiva .CONST comunque viene usata per definire costanti come stringhe e numeri floating point che devono essere immagazzinati in memoria).
Segmenti dati far
I modelli di memoria large e huge usano per default dati far. Quando si usa .FARDATA o .FARDATA? con i modelli di memoria small e medium, l'assemblatore crea il segmento dati far FAR_DATA e FAR_BSS e possiamo accedere a tali variabili come
mov ax, SEG farvar
mov ds, ax
Creazione di Segmenti codice
si potrebbe avere un programma con moduli chiamati da altri moduli e avere entrambi segmenti codice near e far.
Segmento codice near
Spesso il modello di memoria small è la miglior scelta per i programmi che non sono linkati a moduli scritti in altri linguaggi, specialmente se non hai davvero bisogno di avere più di 64Kb per il codice. Usando la direttiva .CODE diciamo all'assemblatore di iniziare un segmento codice per ospitare le nostre istruzioni.
Segmento codice far
Quando hai bisogno di più di 64 Kb per il codice si deve usare uno tra i modelli di memoria medium, large o huge per creare segmenti far. Nel modello di memoria larger l'assemblatore crea segmenti codice differenti per ogni modulo. Se usi invece segmenti codice multipli in un modello di memoria small, compact o tiny il linker ne fa uno solo. Per ogni segmento codice far l'assemblatore chiama ogni segmento MODNAME_TEXT dove MODNAME è il nome del modulo, mentre con un segmento codice near lo chiama _TEXT.
Vediamo un esempio di codice far:
.CODE FIRST ... ... .CODE SECOND ... ...(in questo caso verrebbero creati i segmenti FIRST_TEXT e SECOND_TEXT). Ove il processore esegua una call far o un jump, carica CS con il nuovo indirizzo di segmento. Nota: L'assemblatore assume sempre che CS contenga l'indirizzo del segmento codice corrente o del gruppo.
Inizio e Fine del codice con le direttive .STARTUP e .EXIT
Il modo più facile per iniziare e finire un programma MS-DOS è usando queste direttive nel modulo principale che generano il codice appropriato alla distanza dello stack specificata con .MODEL e cmq non si applicano al modello flat.
Utilizzo:
.CODE .STARTUP .. .EXIT ENDSe non si usa .STARTUP bisogna dare l'indirizzo di partenza come argomento per la direttiva END, ovvero
.CODE start: ... END startCon il default NEARSTACK, .STARTUP fa puntare DS a DGROUP e setta SS:SP relativamente al DGROUP generando il codice seguente:
@Startup: mov dx, DGROUP mov ds, dx mov bx, ss sub bx, dx shl bx, 1 ; If .286 or higher, this is shl bx, 1 ; shortened to shl bx, 4 shl bx, 1 shl bx, 1 cli ; Not necessary in .286 or higher mov ss, dx add sp, bx sti ; Not necessary in .286 or higher Starting and Ending Code with .STARTUP and .EXIT (C) 1992-1996 Microsoft Corporation. All rights reserved. Macro Assembler 6.1 (16-bit) - MSDN Archive Edition Page 40 . . END @StartupUn programma MS-DOS con l'attributo FARSTACK non ha bisogno di aggiustare SS:SP, così .STARTUP fa solo
@Startup: mov dx, DGROUP mov ds, dx . . . END @StartupQuando il programma termina si può ritornare un codice di uscita al sistema operativo e può tornare utile per quelle applicazioni che fanno un controllo su tale valore di ritorno e di solito un codice 0 significa tutto ok. La direttiva .EXIT accetta un codice di uscita da 1 byte come argomento opzionale:
.EXIT 1 ;
.EXIT ; genera il seguente codice che ritorna il controllo a MS-DOS terminando il programma.
; Il valore di ritorno può essere una costante, un riferimento di memoria e va in AL
mov al, value
mov ah, 04Ch
int 21h
Inizializzazione dei registri di segmento
Dai dai ci siamo arrivati!
Prima di utilizzare gli indirizzi segmentati nel programma, dobbiamo inizializzare i registri di segmento. Questo processo di inizializzazione dipende dai registri usati e dall'aver scelte le direttive semplificate o meno in quanto le direttive semplificate gestiscono vari aspetti al posto nostro come abbiamo appena visto. Come sappiamo, la famiglia di processori 8086 usa un sistema di registri di segmento di default per semplificare l'accesso al codice e ai dati. Normalmente, i registri di segmento DS, SS e CS vengono inizializzati all'inizio di un programma. Ecco i passi da seguire per inizializzare i segmenti:
1. Dire all'assemblatore quale segmento è associato con un determinato registro. DEVE saperlo in fase di assemblamento
2. Dire al processore quale segmento è associato con un determinato registro scrivendo il codice necessario per caricare il valore corretto del segmento nel registro di segmento nel processore.
Parliamo con l'assemblatore sui valori dei segmenti...
Questo compito lo facciamo con la direttiva ASSUME (con le direttive semplificate l'assembler genera automaticamente le assunzioni appropriate e .STARTUP setta DS = SS, a meno che non si specifica FARSTACK, permettendo di accedere ai dati sia con SS che con DS). Ecco un esempio di assume con le direttive estese:
ASSUME cs:_TEXT, ds:DGROUP, SS:DGROUP
è anche possibile avere segmenti diversi per i dati e il codice
ASSUME cs:MYCODE, ds:MYDATA, ss:MYSTACK, es:OTHER
Usando la direttiva .CODE l'assemblatore assume che CS sia il segmento corrente.
...e pure due chiacchiere col processore sempre sui valori dei segmenti
L'ultimo passo per inizializzare i segmenti è informare il processore al run time. Come i valori dei segmenti sono inizializzati dipende dal sistema operativo e dall'uso o meno delle direttive semplificate.
Specificare un indirizzo di partenza
L'indirizzo di partenza di un programma determina dove l'esecuzione di un programma inizia (applausi :D). Dopo il sistema operativo carica il programma, semplicemente saltando al suo indirizzo di partenza dando quindi al processore il controllo sul programma. Naturalmente, dietro le quinte è lo scheduler che si occupa di gestire i processi che devono essere "runnati", poi si potrebbe discutere del meccanismo di task switching ben documentato da intel, e cmq come ormai sapete multithread non vuol dire che i processi vengono eseguiti "contemporaneamente", è solo un'impressione, il realtà i processi vengono sempre eseguiti UNO alla volta...ma questa è un' altra storia. Se volete approfondire le meraviglie e le profondità dei sistemi operativi vi consiglio IL librone di Silberschatz, 6 ed. Tanembaum 3 ed non mi piace, si lui è un grande ma fa troppo lo sborone con il suo minix, era già meglio la seconda edizione). Il vero indirizzo di partenza è noto solo al loader (e a qualsiasi gonzo con un PE Editor, un Process viewer, un disasm o un hex editor, cmq..., ndnt). Una nota sul codice rilocabile: (ehm questo discorso vale per le dll o cmq i moduli che vengono caricati all'interno dello spazio di un processo, siccome potrebbe esserci già un modulo ad un certo addr il modulo viene rilocato ovvero messo da un'altra parte da quella prevista e questo è possibile solo se il modulo contiene nel sul PE una relocation table (se non ce l'ha dà errore) che dice al loader dove aggiornare gli indirizzi assoluti in base ad un valore delta calcolato dal loader, questo discorso lo spiego bene nel tut sul PE, ndnt). Questo offset dipende dal tipo di programma.
Programmi con estensione .exe contengono un header (.exe, .ocx. .dll. .sys ecc si chiama PE Header, ndnt) dal quale il loader legge un RVA e lo combina con l'image base che ha deciso per l'exe.
I .com invece non hanno questo header, così per convenzione il loader salta al primo byte del programma. In entrambi i casi la direttiva .STARTUP identifica dove inizia l'esecuzione. per un .exe immediatamente prima l'istruzione dove si vuole che l'esecuzione cominci. In un .com prima della prima istruzione assembly nel codice sorgente. Facciamo un esempio di come dire a un programma dove iniziare l'esecuzione (es. file .com e quindi modello tiny):
_TEXT SEGMENT WORD PUBLIC 'CODE'
ORG 100h
start:
...
_TEXT ENDS
END start
ORG è obbligatoria nel modello di memoria tiny senza la direttiva .STARTUP.
Piazza la prima istruzione all'offset 100h nel segmento codice per lasciare
spazio ai 256 byte (100h) dell'area dati chiamata PSP (Program Segment Prefix,
creato da DOS per tutti i programmi e contiene svariate informazioni per l'esecuzione
dello stesso. Dove sta? Vediamo un esempio (Sempre da AsmJournal), dando uno
sguardo veloce alla struttura di un vecchio file .com:
FFFFh +--------------------+ <- SP
| |
| Stack |
| |
+--------------------+
| |
| Uninitialized Data |
| |
+--------------------+
| |
| COM File Image |
| |
100h +--------------------+ <- IP
| |
| PSP |
| |
0h +--------------------+ <- CS, DS, ES, SS
OK, ma quali informazioni contiene?
[ PSP - Program Segment Prefix ] Offset Size Description ------ ---- ----------- 0h Word INT 20h instruction 2h Word Segment address of top of the current program's allocated memory 4h Byte Reserved 5h Byte Far call to DOS function dispatcher (INT 21h) 6h Word Available bytes in the segment for .COM files 8h Word Reserved Ah Dword INT 22h termination address Eh Dword INT 23h Ctrl-Break handler address 12h Dword DOS 1.1+ INT 24h critical error handler address 16h Byte Segment of parent PSP 18h 20 Bytes DOS 2+ Job File Table (one byte per file handle FFh = available/closed) 2Ch Word DOS 2+ segment address of process' environment block 2Eh Dword DOS 2+ process' SS:SP on entry to last INT 21h function call 32h Word DOS 3+ number of entries in JFT 34h Dword DOS 3+ pointer to JFT 38h Dword DOS 3+ pointer to previous PSP 3Ch 20 Bytes Reserved 50h 3 Bytes DOS 2+ INT 21h/RETF instructions 53h 9 Bytes Unused 5Ch 16 Bytes Default unopened File Control Block 1 (FCB1) 6Ch 16 Bytes Default unopened File Control Block 2 (FCB2) 7Ch 4 Bytes Unused 80h Byte Command line length in bytes 81h 127 Bytes Command line (ends with a Carriage Return 0Dh)Cmq ci fermiamo qui, una trattazione completa esula dallo scopo di questo tutorial, se no davvero non ne esco più:D) ). Il sistema operativo si prende cura di inizializzare il PSP così che devi solo essere sicuro che quest'area esista.
Inizializzare ds
Per l'ennesima volta, DS viene automaticamente inizializzato al corretto valore (DGROUP) se si usa la direttiva .STARTUP. Se non si usa .STARTUP con MS-DOS bisogna fare
mov ax, DGROUP mov ds, axQuesto esempio carica DGROUP ma si può usare qualsiasi segmento o gruppo.
Inizializzare SS e SP
Se si usa la direttiva semplificata .STACK o se si definisce un segmento che ha il tipo combine STACK con le direttive estese SS e SP vengono inizializzate automaticamente (praticamente un ricatto :P iihihhhi).
Per un file .exe l'indirizzo dello stack viene codificato nell'header dell'eseguibile e risolto in fase di caricamento. Per un file .com il loader setta SS = CS e inizializza SP = 0FFFEh
Scegliere le convenzioni del linguaggio
Questa facoltà facilita la compatibilità con i linguaggi di alto livello (qualora dovesse servire) determinando la codifica interna per i nomi dei simboli pubblici ed esterni, il codice generato dalla procedura di inizializzazione e il cleanup, l'ordine con il quale gli argomenti devono essere passati a una INVOKE (non a caso nel primo tutorial della saga anche iczelion accenna a questa cosina). La programmer's guide del Masm ci dice che PASCAL, BASIC e FORTRAN sono uguali. C e SYSCALL hanno la stessa calling convention ma differenti naming convention. Boh, vediamo :)
| Note finali |
Saluto Ntoskrnl (ovviamente :P grazie davvero per le tue note e per aver corretto qualche mio strafalcione, attualmente 02/08/2004 in Norvegia, sulle isole Lofoten, mi ha appena mandato sms), albe, Quequero, andreageddon, evilcry (...), Ironspark, i satelliti di marte :D , ZaiRoN, MrCode, la nostra Giulia (giù io aspetto sempre il tuo Tasm vs Masm :P), e tutti quelli che hanno e hanno avuto la sfortuna di conoscermi :P
| Disclaimer |
Sono contento di averlo fatto, ho imparato molto. Come sono andato?