Pochi giorni fa sul nostro forum della UIC, Andy74 riscontra su un semplice programmino scritto da lui un errore del linker che non avevo mai visto: "..Invalid Fixup Record Found..."
Questo mi ha portato ad approfondire la cosa (cosa diavolo è un fixup record??)e a trovare delle informazioni molto interessanti per quei kamikaze che sono riusciti a fagocitarsi sto tutorialone e ad arrivare sino in fondo, spingendomi ad aggiornare questo tute. Per l'articolo originale vi rimando niente meno che a un articolo di Pietrek http://www.microsoft.com/msj/0797/hood0797.aspx
Altra fonte interessante e a cui vi consiglio di fare riferimento è http://www.giobe2000.it nella sezione tutorial troverete spiegazioni sull'assemblatore e il linker ("Come l'assemblatore traduce il codice sorgente" ...), anche se questo fixup record lo spiego meglio io :P ehhehehe
Naturalmente si fa riferimento al Masm, con buona pace per i fans del Tasm ;) Dal sito di Giobe (MITIKO): "...Il compito principale dell'assemblatore è quello di tradurre il testo ASCII (codice sorgente, ASM o codice Assembly) che abbiamo appena prodotto in ambiente editor nel corrispondente Codice Oggetto, OBJ, analizzando con cura le singole parole per controllarne forma e sostanza (ndLonelyWolf: Sintassi e Semantica)...Il meccanismo usato da un assemblatore per tradurre le stringhe in numeri è piuttosto semplice e ripetitivo; esso contiene delle tabelle di conversione con tutti i mnemonici da una parte e i numeri hex corrispondenti (opcode) dall'altra. Esso analizza le righe di codice di ogni stringa mnemonica (istruzione, codice assembly) associa loro una sequenza di bytes (codice macchina) e un numero progressivo a 16 bit (indirizzo corrente); quest'ultimo serve per localizzare con certezza l'inizio di determinati gruppi di istruzioni a cui il programma desidera riferirsi...(ndLonelyWolf: a questo punto giobe basandosi su un programmino mostra passo passo questa operazione, vi consiglio di farvi un giro 'su' ;D Uhmmm...nella sua analisi di 2 file obj, a un certo punto il grande Giobe dice che - www.giobe2000.it/Tutorial/Cap02/Pag/cap02-036.html - in tali file, oltre agli opcode e a determinate stringhe ci sono delle sequenze di bytes non documentate comuni ai 2 file obj...beh a dirla tutta, i file obj non sono undocumented. Passando al setaccio Google come al solito - e cazzo, prima o poi la targhetta come utente dell'anno me la daranno!! - ho trovato il documento allegato al tutorial:
INTRODUCTION
============
This document is intended to serve a purpose that up until now has
been performed by the LINK source code: to be the official definition
for the object module format (the information inside .OBJ files)
supported by Microsoft's language products. The goal is to include all
currently used or obsolete OMF record types, all currently used or
obsolete field values, and all extensions made by Microsoft, IBM, and
others.
è un po'vecchiotto 5/92, ma i veri bongustai come dei sommellier apprezzeranno il prodotto d'annata ;D )
Come l'assemblatore tratta le etichette?
Ritiene etichette tutte le altre parole non incluse nelle sue tabelle di conversione: le etichette sono Indirizzi espressi in forma simbolica ; uno dei compiti dell'assemblatore è proprio quello di predisporre la loro raccolta nella Tabella dei Simboli...(NdLonelyWolf: sempre da Giobe si legge che la famosa Tabella dei Simboli risiede nel file .lst prodotto dal compilatore MASM, organizzato tra l'altro in pratiche pagine stampabili...leggete gente, leggete!) Per completare la traduzione di un codice sorgente l'assemblatore deve compiere 2 passate (cioè deve leggere il testo 2 volte): Nella prima scansione si occupa solo di creare la Tabella dei Simboli, cioè annota tutte le etichette che trova e associa i rispettivi valori, solo nella seconda scansione crea il codice macchina, avendo a disposizione tutti i dati necessari per compilarlo (i bytes del codice mnemonico). Per concludere, dopo le 2 passate del compilatore abbiamo un codice oggetto Quasi funzionante. Se invece ci son riferimenti irrisolti (cioè etichette EXTRN non definite) al posto dei 2 bytes dell'indirizzo ci saranno 2 bytes a 00h (NdLonelyWolf: li lascia temporaneamente vuoti, tenete a mente sta cosa)e il codice non potrà essere eseguibile fino a quando non saranno disponibili i valori effettivi. La presenza di riferimenti irrisolti rende necessario l'intervento del linker...
Il compito principale del Linker è quello di trasformare il codice oggetto (.obj) in eseguibile (.exe)... Recupera gli indirizzi lasciati vuoti dal compilatore e li sostituisce con quelli rilocati. Se l'oggetto ha riferimenti esterni ad altri oggetti, provvede a recuperarli e ad unirli in un unico programma eseguibile...Predispone all'inizio del file exe una intestazione contenente le informazioni necesarie al DOS per caricarlo (rilocarlo) in memoria nel punto desiderato. La rilocabilità del programma exe è da ritenersi a livello segmento: spetta al DOS stabilire, nel preciso momento del caricamento in RAM, quale sarà la prima area libera, adattando ad essa tutti gli indirizzi di segmento dell'eseguibile...oltre al file exe viene anche creato un file .map...che contiene il resoconto della situazione relativa in memoria di ciascun segmento in termini di quantità di byte s occupati (Length) e di locazione iniziale Start e finale Stop; la sua osservazione può aiutarci a capire il significato delle scelte di "Allineamento" fatte.(NdLonelyWolf: Giobe fa una trattazione approfondita sui file .map che consiglio fortemente di leggere)...
Bene, continuiamo l'immersione...parola a Pietrek ora (e scusate se è poco :P):
...i componenti principali di un modulo oggetto sono il codice macchina e i dati. I raw bytes che costituiscono il codice e i dati sono memorizzati in blocchi contigui chiamati sezioni...se hai VC++ installato puoi vedere le sezioni all'interndo di un file obj con il programma DUMPBIN. esegui il comando DUMPBIN nomefile.obj
Elenco delle sezioni più comuni:
.text Machine code instructions. .data Initialized data. .rdata Read only data. OLE GUIDs are stored here, among other things. .rsrc Resources. Produced by the resource compiler, and placed into RES files. Linker copies it to the executable. .reloc Base relocations. Produced by the linker. Not found in OBJs. .edata The exported function table. Created by the linker and placed in an EXP file. Linker copies it to the executable. .idata Imported function table in an executable file. .idata$XXX Portions of an imported function table. The librarian creates these sections in an import library. The linker combines them into the...Potreste meravigliarvi di come il linker decida di disporre il codice e le sezione dati nell'eseguibile finale. Il linker ha un elaborato set di regole che devono essere seguite. Infatti, i compiti di un linker sono così complicati che effettua due passaggi. Il primo passaggio permette al linker di vedere con cosa lavorerà mentre nel secondo applicherà tutte le sue regole. La regola primaria è che il linker deve mettere tutto il codice e i dati da ogni .obj nell'eseguibile. Se passiamo al linker 3 file .obj, allora il codice e i dati presenti in questi 3 .obj devono essere in qualche modo incorporati nell'eseguibile. Comunque, il lavoro del linker non si limita a prendere queste raw sections da ogni .obj e concantenarle. Il linker concatena/combina tutte le sezioni con lo stesso nome. Per esempio, se ognuno dei 3 file .obj avesse una sezione .text, l'eseguibile risultante avrebbe una singola sezione .text formata dalla concatenazione delle 3 sezioni nell'ordine con il quale sono state incontrate. UN'altra regola osservata dal linker è che la sequenza di sezioni nell'eseguibile è dettata dall'ordine con il quale il linker processa le sezioni. Il linker lavora prendendo la lista dei file .obj esattamente come viene passata dalla linea di comando. Comunque, la regola di combinare sezioni con lo stesso nome ha la precedenza.
final .idata section in the executable. .CRT Tables of initialization and shutdown pointers in the executable that are used by the Microsoft C++ runtime library. .CRT$XXX Initialization and shutdown pointers in OBJs, prior to the linker combining them in the executable. .bss Uninitialized data. .drectve OBJ file section containing linker directives. Not copied to executable. .debug$XXX COFF symbol table information in an OBJ file.
La figura mostra 3 file .obj costituite dalle relative sezioni, e le frecce indicano come il linker le raggruppa.
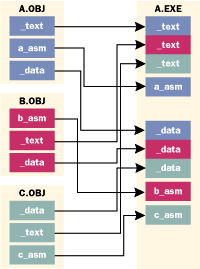
(NdLonelyWolf: non mi sembra così difficile da capire :P è ovvio che se dalla linea di comando i 3 file fossero passati in ordine diverso, questa disposizione finale non sarebbe più valida)
Se una sezione contiene un $ (ad esempio .idata$4) il $ e tutto quello che segue sarà tolto dall'eseguibile. Comunque, prima che il linker lo faccia, combina le sezioni con i nomi corrospondenti fino a $. La porzione di nome dopo il $ è usata per disporre le sezioni .obj nell'eseguibile. Queste sezioni sono ordinate alfabeticamente, basate sulla porzione di nome dopo il $. Per esempio, tre sezioni chiamate foo$c, foo$a e foo$b saranno combinate in una singola sezione foo nell'eseguibile. I dati in questa sezioni cominceranno con i dati di foo$a continuando con foo$b e foo$c. Questa combinazione automatica delle sezioni è usata anche per creare tabelle dati necessarie per l'inizializzazione dei costruttori e distruttori C++. Oltre a queste regole di combinazione $, il win32linker ha qualche altro caso speciale nella manica. Sezioni con l'attributo codice sono trattate con preferenza e messe per prime nel file eseguibile. Successivamente il linker mette ogni sezione dati non inizializzata - incluse i dati globali non inizializzati - poi vengono i dati inizializzati inclusa la sezione .data così come la sezione dati generata dal linker come .reloc. Tuttavia oggi come oggi è raro vedere una sezione .bss in un eseguibile. Il Linker Microsoft (link.exe) fa un merge della sezione .bss nella sezione .data che è la principale sezione dati inizializzati usata dal compilatore. Ma questo accade solo se l'eseguibile è per un sottosistema oltre al posix e la versione del sottosistema è > 3.5. Eventuali altre sezioni che contengono dati non inizializzati vengono lasciate da sole. Lavorando all'indietro, dalla fine dell'eseguibile, se c'è una sezione .debug nel file .obj questa viene piazzata per ultima nell'eseguibile. In assenza della sezione .debug il linker prova a mettere la sezione .reloc per ultima, perchè in molti casi, il loader Win32 non avrà bisogno di leggere queste informazioni di rilocazione. Ancora un'altra eccezione alle 2 regole basilari sotto Win32 sono le sezione rimovibili. Queste sezioni esistono in un file .obj ma il linker non le copia nell'eseguibile. Queste sezioni tipicamente hanno gli attributi LINK_ REMOVE e LINK_INFO (vedi WINNT.H) e sono chiamate .drectve.
Se guardi un file .obj compilato con VC++ vedrai che i dati nella sezione .drectve probabilmente assomigliano a qualcosa di questo tipo:
-defaultlib:LIBC -defaultlib:OLDNAMES
Se questi dati sembrano sospetti come argomeni da linea di comando al linker, sei sulla strada giusta. Puoi vedere altre prove di questo quando usi il modificatore __declspec(dllexport), per esempio:
void __declspec(dllexport) ExportMe( void ){...}
farà si che la sezione .drectve contenga
-export:_ExportMe
Fixups e Rilocazioni
Perchè i compilatori non possono semplicemente generare file eseguibili direttamente dal file sorgente, eliminando così il bisogno di usare un linker? (NdLonelyWolf: ...retorica made in Pietrek ;) ROTFL btw, Pietrek fondamentalmente dice: "...resolving references = fixups..")
La ragione primaria è che molti programmi non consistono in un solo file sorgente. I compilatori sono specializzati nel prendere un singolo file sorgente e produrre raw code, equivalente al codice macchina. Ma un file sorgente può contenere riferimenti a codice o a dati esterni al file sorgente e un compilatore non può generare esattamente il codice giusto per chiamare quella funzione o accedere a quella variabile. Invece , l'unica opzione del compilatore è di includere informazioni extra nel file di output che descrive il codice esterno o i dati. Il termine per questa descrizione del codice esterno o riferimento ai dati è un fixup. Mettendoli bruscamente, il codice che il compilatore genererebbe per accedere a funzioni esterne e variabili non sarebbe corretto, e dovrebbe essere fixato in seguito.
Prendiamo una chiamata a una funzione in C++:
//...
Foo();
//...
I byte esatti emessi dal compilatore VC++ 32bit sarebbero E8 00 00 00 00 (0xE8 è l'opcode dell'istruzione CALL NdLonelyWolf e qui un po'ci si ricollega a quello che diceva il buon Giobe). La successiva DWORD dovrebbe contenere l'offset alla funzione Foo (relativa all'istruzione CALL). E' abbastanza chiaro che Foo probabilmente NON sarà davvero a 0 byte dall'istruzione CALL. Questo codice non funzionerebbe come ci aspettiamo e "rotto" è necessita di essere fixato. Nell'esempio, il linker necessita di sostituire quella DWORD con l'indirizzo corretto di Foo. Nel file eseguibile, il linker scriverà una DWORD con il relative address di Foo. E come fa il linker a sapere che DEVE fare questa cosa? è il Fixup Record che lo dice. Come fa il linker a sapere dove sta la funzione Foo? Il linker conosce tutti i simboli nell'eseguibile perchè è responsabile della disposizione e combinazione dei componenti nell'eseguibile.
Parliamo di questi fixup records. Per i file .obj Intel-based ci sono solo 3 tipi di fixup record che si incontrano normalmente. I primi sono relativi a fixup 32bit e sono conosciuti come REL32 fixups (Per i curiosi, corrispondono a IMAGE_REL_I386_REL32 #define in WINNT.H). Nell'esempio di prima con la funzione Foo, ci sarà un fixup record REL32 e avrà l'offset della DWORD che il linker dovrà sovrascrivere con il valore appropriato (NdLonelyWolf: mi pare evidente che il fixup record non si applica SOLAMENTE ai riferimenti esterni, ma alla 'normale' gestione delle rilocazioni).
Eseguendo DUMPBIN /RELOCATIONS (NdLonelyWolf: ehm, nell'articolo ci sono i sorgenti di esempio, per cui Pietrek ovviamente fa riferimento a quelli, voi fidatevi del vostro Lupo Solitario ;P) sul file .obj ottenuto dal codice di sopra vedremo qualcosa di questo tipo:
Symbol Symbol
Offset Type Applied To Index Name
-------- ---- ---------- ------ ------
00000004 REL32 00000000 7 _Foo
|
In italiano, questo fixup record (andy74, capisci ora in che contesto il linker diceva che trovava un invalid fixup record?) dice che il linker necessita di calcolare il relative offset della funzione Foo e scrivere quel valore all'offset 4 nella sezione. Poichè questo fixup record è necessario solo al linker per la creazione dell'eseguibile viene poi scartato e non appare nell'eseguibile. Perchè allora molti eseguibili contengono una sezione .reloc?
E'in questo caso che occorre il secondo tipo di fixup record. Consideriamo il seguento programma:
int i;
int main()
{
i = 0x12345678;
}
Il prode VC++ genererà questa istruzione per l'assegnamento nell'eseguibile: MOV DWORD PTR [00406280],12345678
La cosa interessante è la parte [00406280] dell'istruzione. Referenzia una locazione FISSATA di memoria e assume che la DWORD che contiene la viarabile i sia 0x6280 bytes sopra l'indirizzo di caricamento dell'eseguibile, che per default è 0x400000. Consideriamo cosa accadrebbe se l'eseguibile non venisse caricato nel valore di default. Diciamo che il Win32 loader lo carica 2Mb in alto in memoria (e quindi a 0x600000). In questo caso [00406280] necessiterebbe di essere aggiustato in [00606280]. E'per occasioni come questa che DIR32 (Direct 32) fixups vengono usati nei file .obj. Questi fixup diretti significano la locazione dove l'indirizzo attuale (diretto/immediato) di qualcosa necessita di essere attaccato/inserito. Implicitamente, significa anche le locazioni dove l'indirizzo di caricamento (IMAGE BASE) dell'eseguibile è significativo. Quando si crea un eseguibile, il loader prende il fixup DIR32 dal file .obj e crea la sezione .reloc. Prima che questo accada, esegui DUMPBIN /RELOCATIONS sul file .obj:
Symbol Symbol
Offset Type Applied To Index Name
-------- ----- ---------- ------ ------
00000005 DIR32 00000000 4 _i
|
Questo fixup record dice che il linker necessita di calcolare l'indirizzo diretto a 32 bit della variabile _i e scrivere quel valore all'offset 5 nella sezione. La sezione .reloc in un eseguibile è basilarmente una serie di indirizzi nell'eseguibile dove la differenza tra l'indirizzo di caricamento di default e quello attuale deve essere calcolata. Per default, il linker crea l'eseguibile in modo che la sezione .reloc non serva al Win32 Loader. Comunque, quando il loader necessita di caricare un eseguibile in un'altra posizione la sezione .reloc permette a tutti i riferimenti diretti al codice e ai dati di essere aggiornati. Il terzo tipo di fixup che si trova comunemente nei file .obj Intel è DIR32NB (Direct 32, No Base) viene usato per le informazioni di debug. Uno dei lavori secondari del linker è di creare informazioni di debug che includono i nomi delle funzioni e delle variabili assieme ai loro indirizzi. Poichè solo il linker conosce dove tutte le variabili e le funzioni finiscono, il fixup DIR32NB è usato per indicare i posti nelle informazioni di debug, dove l'indirizzo di una funzione o variabile è necessario. La differenza chiave tra i fixup DIR32 e DIR32NB è che i valori patchati per DIR32NB non includono l'indirizzo di caricamento di default dell'eseguibile...(NdLonelyWolf: a questo punto Pietrek spiega come funzionano le librerie e le relazioni con i file .obj se volete favorire..non fate complimenti :D) ...
Librerie
(NdLonelyWolf: mescolo ora anche dell'altra robina estratta dal seguito di quell'articolo di Pietrek sempre su Under the Hood http://www.microsoft.com/msj/0498/hood0498.aspx) Dalla prospettiva del Linker, un file .LIB è solo una collezione di file .OBJ. La tabella dei contenuti in un file .LIB è una lista di tutti i simboli da tutti gli obj contenuti nella libreria. Per ogni simbolo, la tabella dei contenuti indica anche da quali file obj il simbolo proviene. Questa mappatura di un nome di simbolo al relativo obj permette al linker di procurare velocemente solo il file obj dalla lib di cui necessita, ignorando il resto della libreria.
La struttura COFF dei file .LIB
...intanto sappi che in COFF le parole "archive" e "library" sono usate scambievolmente. Ricorda poi che i componenti di un file .LIB sono riferiti come "membri". Diciamo che un file .LIB è veramente solo una serie di contigui membri archivio..ogni membro archivio corrisponde a un file .obj (NdLonelyWolf: ? dovrebbe essere più chiaro andando avanti..)
Tutte le .LIB COFF cominciano con un header di 8 bytem che quando visualizzato come ASCII mostra proprio "!
 La figura mostra il formato
del linker member dei nomi. Dopo IMAGE_ARCHIVE_MEMBER_HEADER c'è una DWORD con
il numero di simboli nella libreria. Successivamente c'è un array di DWORD offset
ad altri membri archivio nella libreria. Dopo l'array DWORD c'è una serie di
string Null-Terminate con i nomi dei simboli. Ogni entry successiva nell'array
DWORD corrisponde alla successiva stringa nella tabella delle stringhe.
La figura mostra il formato
del linker member dei nomi. Dopo IMAGE_ARCHIVE_MEMBER_HEADER c'è una DWORD con
il numero di simboli nella libreria. Successivamente c'è un array di DWORD offset
ad altri membri archivio nella libreria. Dopo l'array DWORD c'è una serie di
string Null-Terminate con i nomi dei simboli. Ogni entry successiva nell'array
DWORD corrisponde alla successiva stringa nella tabella delle stringhe.  Il formato degli altri archivi non-names è altrettanto semplice. Si tratta solo
di un archive member header seguito da un file .obj. Se non hai familiarità
con il layout di un file .obj esso consiste in un IMAGE_FILE_HEADER seguito
da una o più strutture IMAGE_SECTION_HEADER , una per ogni codice o sezione
dati. Segue il raw code e i dati per le sezioni. La Symbol Table correla i nomi
dei simboli a una specifica locazione nel codice e dati dell'obj. Tutte queste
strutture sono le stesse usate nel file eseguibile, e sono descritte in WINNT.H.
Il formato degli altri archivi non-names è altrettanto semplice. Si tratta solo
di un archive member header seguito da un file .obj. Se non hai familiarità
con il layout di un file .obj esso consiste in un IMAGE_FILE_HEADER seguito
da una o più strutture IMAGE_SECTION_HEADER , una per ogni codice o sezione
dati. Segue il raw code e i dati per le sezioni. La Symbol Table correla i nomi
dei simboli a una specifica locazione nel codice e dati dell'obj. Tutte queste
strutture sono le stesse usate nel file eseguibile, e sono descritte in WINNT.H.
In alcune circostanze, è meritevole combinare 2 o più OBJ insieme in un singolo file, che può essere dato poi al linker. L'esempio classico di questo è la C++ Runtime library (RTL). La C++ RTL è composta da numerosi file sorgente che sono compilati, e i risultanti OBJ sono combinati un una libreria. per VC++, la standars, single thread, versione statica della runtime library è chiamata LIBC.LIB. Ci sono altre variazioni per il debugging (ad esempio LIBCD.LIB) e multithreading (LIBCMT.LIB). I file di libreria di solito hanno l'estensione .LIB e consistono in un header di libreria seguito dai raw data dell'obj contenuto. L'header della libreria informa il linker di quali simboli (funzioni e variabili) possono essere trovati nei seguenti OBJ così come in quale Obj un certo simbolo risiede. Il contenuto di una libreria si può vedere con DUMPBIN /LINKERMEMBER. Senza scendere nei dettagli del perchè, specificando :1 o :2 l'output è più leggibile. Per esempio, usare DUMPBIN su penter.lib (VC++ 5.0) produce:
6 public symbols
180 _DumpCAP@0
180 _StartCAP@0
180 _StopCAP@0
180 _VERSION
180 __mcount
180 __penter
|
Quel 180 davanti ogni simbolo indica che il simbolo (ad esempio _DumpCAP@0) può essere trovato in un file .obj iniziando 0x180 byte nella libreria. Come si vede, penter.lib ha solo un obj. File .lib più complessi sono composti di più file .obj, così che l'offset che precede il simbolo è diverso. A differenza degli obj passati sulla linea di comando, il linker non deve includere ogni obj in una libreria nell' eseguibile finale. Il linker non includerà alcun codice obj o dati da una libreria obj a meno che non ci sia un riferimento ad almeno un simbolo da/in quel file .obj, quindi vengono inclusi solo se direttamente referenziati.
Un simbolo in una libreria può essere referenziato (e quindi l'obj incluso) in 3 modi. 1) Può esserci un riferimento diretto a un simbolo da uno degli espliciti .obj. Per esempio, se dovessi chiamare la funzione printf da un file sorgente che ho scritto, ci sarebbe un riferimento (e un fixup) generato per esso nel mio file .obj. Quando viene creato l'eseguibile il linker cerca i relativi file LIB per l'OBJ contenente il codice printf e include il file obj che trova. 2) Può esserci un riferimento indiretto. Indiretto significa un obj incluso con il primo metodo contenente riferimenti a simboli in un altro file OBJ nella libreria. Questo secondo obj può a sua volta referenziare simboli in un terzo file obj nella libreria. Ed'è proprio questo uno dei compiti più rilevanti del linker, tracciare e includere ogni file .obj di cui sono stati referenziati dei simboli, anche se qualcuno di questi è localizzato da 49 livelli di indirezione. Quando il linker cerca un simbolo, cerca i file .LIB nell'ordine in cui li ha incontrati sulla linea di comando. Comunque, una volta che un simbolo è stato trovato in una libreria, quella libreria diventa la libreria "preferita" da cui cominciare future ricerche. La libreria perde il suo stato di libreria favorita quando un simbolo non viene trovato in tale libreria. In questo caso, viene ricercata la successiva libreria nella lista del linker.
Articolo Microsoft Knowledge Base - 31998 (How the Linker Searches the Libraries)
Il linker cerca gli external non risolti nel seguente ordine: trova tutti i moduli nella libreria che definiscono l'external corrente non risolto.
Processa questi moduli. Il linker lavora su quella libreria fino a quando non viene presa in considerazione una nuova external non risolta. Allora avanza alla libreria successiva. In maniera simile, il linker effettua delle passate sull'intero set di librerie. Dopo l'ultima, se viene preso in considerazione una nuova external non risolta riparte dalla prima libreria e fa un'altra passata. I problemi possono essere evitati non usando riferimenti cross-library bidirezionali (cioè, evitare dalla libreria A di chiamare qualcosa nella libreria B che chiama qualche altra cosa nella libreria A).
Strutturalmente, le import libraries non sono diverse dalle librerie regolari. Quando risolvono simboli, il linker non conosce la differenza tra una import library e una libreria regolare (sotto il formato Win32 COFF). Il linker risolve le chiamate alle funzioni DLL nello stesso modo con cui risolve funzioni interne statiche. L'unica differenza è che quando viene chiamata una funzione in una dll, il file obj nella import library fornisce i dati per l'import table dell'eseguibile piuttosto che il codice per la funzione attuale. I dati che una import library fornisce per una API importata vengono mantenuti in diverse sezioni i cui nomi iniziano tutti con .idata (ad esempio .idata$4, .idata$5 e .idata$6). La sezione .idata$5 contiene una singola DWORD che, quando l'eseguibile viene caricato, contiene l'indirizzo della funzione importata. Se presente, la sezione .idata$6 contiene il nome della funzione importata (NdLonelyWolf: guarda il DUMPBIN sotto). Quando l'eseguibile viene caricato in memoria, il Win32 Loader usa questa stringa per chiamare la GetProcAddress per la funzione effettivamente importata.
Pietrek dice: Come avevo scritto nell'articolo del Luglio 1997, il linker mette insieme le sezioni con lo stesso nome ma non include il $. La porzione dopo il $ è usata per ordinare le sezioni. Perciò, tutte le sezion .idata$4 vengono messe nell'eseguibile in maniera contigua, seguite dalle sezioni .idata$5 completando con tutte le sezioni .idata$6. L'ordinamento e la combinazione da parte del linker delle sezioni è ciò che costruisce la IAT e altre parti della import table nell'eseguibile finale.
Creazione delle Import Tables
...Tutte le informazioni riguardo le funzioni importate dalla DLL risiedono in una tabella nell'eseguibile conosciuta come import table. Quando sta in una sezione a se'stante, questa sezione viene chiamata .idata. Poichè le imports sono così vitali per gli eseguibili Win32, potrebbe sembrare strano che il linker non abbia alcuna speciale conoscenza sulle import tables. O meglio, il linker non sa o non si preoccupa se una funzione che hai chiamato risiede in un'altra DLL o all'interno dello stesso eseguibile. Il modo in cui questo viene compiuto è tutto molto intelligente. Seguendo semplicemente la combinazione delle sezioni e le regole descritte sopra, il linker crea la import table, apparentemente inconsapevole dello speciale significato della tabella. Diamo un'occhiata ad alcuni frammenti di una import library per veder come il linker compia questa funzione. Ecco una porzione del DUMPBIN sulla libreria USER32.LIB:
1121 public symbols
EA14 _ActivateKeyboardLayout@8
...
Archive member name at EA14: USER32.dll/
...
SECTION HEADER #2
.text name
RAW DATA #2
00000000 FF 25 00 00 00 00 .%....
...
SECTION HEADER #4
.idata$5 name
RAW DATA #4
00000000 00 00 00 00 ....
...
SECTION HEADER #5
.idata$4 name
RAW DATA #5
00000000 00 00 00 00 ....
...
SECTION HEADER #6
.idata$6 name
RAW DATA #6
00000000 00 00 41 63 74 69 76 61 | 74 65 4B 65 79 62 6F 61 ..Activa|teKeyboa
00000010 72 64 4C 61 79 6F 75 74 | 00 00 rdLayout|..
...
COFF SYMBOL TABLE
...
003 00000000 SECT2 notype () External | _ActivateKeyboardLayout@8
Ovviamente si presume
che nel nostro programma sia stata chiamata l'API ActivateKeyboardLayout. Un
fixup record per _ActivateKeyboardLayout@8 può essere trovato nel file .obj.
Dall'header dell'USER32.LIB il linker determina che quella funzione può essere
trovata nel file .obj all'offset 0xEA14. A questo punto al linker viene commissionato
il compito di includere il contenuto di questo .obj nel eseguibile finito. Dall'output
del DUMPBIN qua sopra di rileva una varietà di sezioni portate dal file .obj
inclusa .text, idata$5, .idata$4 e .idata$6. Nella sezione .text ( SECTION HEADER
#2) c'è un JMP (0xFF 0x25). In basso, nella COFF symbol table alla fine si vede
che _ActivateKeyboardLayout@8 risolve questo JMP nella sezione .text (SECT2).
Così il linker aggancia (hooks up) la CALL ad ActivateKeyboardLayout a quel
jump. Il linker combina le sezioni .idata$xxx in una singola sezione .idata
nell'eseguibile. Se ci fossero altre funzioni prese da USER32.LIB, le loro sezioni .idata$4, .idata$5 e .idata$6 sarebbero messe insieme nel mix. Il risultato sarebbe che tutte le sezioni .idata$4 creerebbero un array, mentre tutte le .idata$5 ne creerebbero un altro...Se sei familiare con il termine "Import Address Table" questo processo indica come questa tabella viene creata. I raw data per la sezione .idata$6 contiene la stringa ActivateKeyboardLayout. Questo è come il nome della funzione importata venga messo nella IAT. Il punto importante è che la creazione di una import tablenon è un compito oneroso per il linker. Fa solo il suo lavoro seguendo le regole descritte sopra.
Creazione della Export Table
Oltre a creare una import table per l'eseguibile, un linker è anche responsabile per la creazione dell'opposto: la export table. Qui, il lavoro del linker è sia difficile che facile. Nel primo passo, il linker ha il compito di collezionare informazioni su tutti i simboli esportati e creare una tabella di funzioni esportate. Durante questo primo passaggio, il linker crea la export table e la scrive in una sezione chamata .edata in un file .obj.
Questo file .obj è standard in tutti gli aspetti eccetto che usa l'estensione .EXP al posto di .OBJ. Si può sempre usare DUMPBIN per esaminare il contenuto dei file EXP che sembrano accumularsi in presenza delle DLL che vengono create. Durante il suo secondo passaggio, il lavoro del linker si riduce semplicemente a trattare il file .EXP come un normale .OBJ. Questo significa che .edata nel file .obj sarà incluso nell'eseguibile. Abbastanza sicuramente, se nell'eseguibile si trova una sezione .edata sarà la export table. In questi giorni comunque, trovare una sezione .edata è una cosa abbastanza rara. Sembra che se l'eseguibile usa Win32 console o il sottosistema GUI, il linker automaticamente la unisce con la sezione .rdata se presente.
Credo di aver finito e di essere sopravvisuto, anche se con i vestiti ridotti a brandelli, le vesciche e la disidratazione :D rotfl Spero di non aver trascritto boiate e soprattutto che possa essere utile a tutti coloro che si avvicinano al mondo incantato della programmazione in assembler, come lo è stato per me...credo :P.
Fatemi sapere!
Alla prossima (ehi, però non vi abituate adesso, massa di viziati! :P ahahah)
Follemente vostro
Lonely Wolf
PS.
BIBLIOGRAFIA
A parte i link che trovate nel tute, mi sono massiciamente basato sul libro MAsm Programmer's guide (doc.ddart.net/asm/Microsoft_ MASM_Programmers_Guide_v6.1), il sito msdn.microsoft.com per le info sulle calling convention, e testi vari da cui ho estrapolati piccoli pezzi, come Memory in SPARC SPARC Assembly Language Mark Smotherman Clemson University da cui ho estrapolato il pezzettino su BSS, poi vabbeh, ho chiesto qua e la in chan per farmi spiegare alcune cosette (grazie).
|
Note finali |
Saluto Ntoskrnl (ovviamente :P grazie davvero per le tue note e per aver corretto qualche mio strafalcione, attualmente 02/08/2004 in Norvegia, sulle isole Lofoten, mi ha appena mandato sms), albe, Quequero, andreageddon, evilcry (...), Ironspark, i satelliti di marte :D , ZaiRoN, MrCode, la nostra Giulia (giù io aspetto sempre il tuo Tasm vs Masm :P), e tutti quelli che hanno e hanno avuto la sfortuna di conoscermi :P
|
Disclaimer |
Sono contento di averlo fatto, ho imparato molto. Come sono andato?