|
Low
level speed optimization | ||
|
Data |
by Spider |
|
|
1 gennaio 2004 |
Published by Quequero | |
|
|
Grazie spi! |
Tutti sanno che una cosa è impossibile da realizzare, finché arriva uno sprovveduto che non lo sa e la inventa. |
|
.... |
|
.... |
|
Difficoltà |
( )NewBies ( )Intermedio (X)Avanzato ( )Master |
|
In questo tutorial daremo uno sguardo al bellissimo mondo dell'ottimizzazione della velocità, in particolare di quel tipo di ottimizzazione che è prerogativa dei programmatori in linguaggio assembly e spesso sottovalutato dagli altri: l'ottimizzazione a basso livello.
|
Introduzione |
|
Tools usati |
Prerequisiti:
- Conoscenza del funzionamento generale di un processore e della programmazione in linguaggio assembly.
Tools usati:
- Masm o qualunque altro assembler.
|
Essay |
Indice:
1.0 - Ottimizzazione della velocità
1.1 - Tre "livelli" di ottimizzazione
2 - Implementazioni hardware
2.1 - Pipeline
2.1.1 Throughput e latenza
2.1.2 Il problema degli stalli
2.1.2.1 Criticità strutturali
2.1.2.2 Criticità sul controllo
2.1.2.3 Criticità sui dati
2.1.2.4 Eliminazione delle criticità
2.2 - Memoria cache
2.2.1 - Hit rate
2.2.2 - Cache a mappa diretta
2.2.3 - Cache completamente associativa
2.2.4 - Cache set-associative
2.2.5 - Strategia write-through
2.2.6 - Strategia write-back
2.3 - Parallelismo
2.3.1 - Architetture superscalari
2.3.2 - Architetture superpipeline
2.3.3 - Dipendenze
2.3.4 - Esecuzione out-of-order
2.3.5 - Renaming
2.3.6 - Esecuzione speculativa
3 - Famiglia di processori Intel
3.1 - Visione d'insieme
3.1.1 - Plain old Pentium
3.1.2 - Pentium Pro
3.1.3 - Pentium with MMX
3.1.4 - Pentium II
3.1.5 - Pentium III
3.1.6 - Pentium 4
4 - Ottimizzazione del codice
4.1 - Allineamento dei dati
4.2 - Ottimizzazione dell'uso della cache
4.3 - Ripetizione del codice
4.4 - Generazione dell'indirizzo
4.5 - Pairing
4.6 - Decoding
4.7 - Fetching
4.8 - Renaming dei registri
4.9 - Esecuzione Out-Of-Order e selezione delle istruzioni
4.10 - Partial Stalls
4.10.1 - Partial Register Stalls
4.10.2 - Partial Flag Stalls
4.10.3 - Partial Memory Stalls
4.11 - Istruzioni di salto
4.11.1 - Predizione statica
4.11.2 - Predizione dinamica (e pattern recognition)
4.11.3 - Return Stack Buffer
4.11.4 - Ottimizzare i jumps
4.12 - Loop Unrolling
4.13 - Identificare il processore
4.14 - Tips & tricks
5 - Bibliografia
1.0 - Ottimizzazione della velocità
Durante o dopo la stesura di un programma o
parte di esso, può capitare di incorrere in un problema: il vostro codice, pur
essendo in grado di svolgere le funzioni per cui è stato ideato, lo fa in tempi
eccessivamente lunghi. E' quindi necessario ottimizzare in modo da raggiungere
prestazioni migliori.
E' impossibile dare delle regole generali per capire quando e come ottimizzare.
Ad ogni modo, non bisogna commettere l'errore di ottimizzare TUTTO il codice del
programma. E' necessario capire quali procedure sono particolarmente
"critiche" e tralasciare il resto. L'ottimizzazione è un processo che
può rivelarsi molto complesso e può diminuire notevolmente la leggibilità del
codice, e va quindi fatto con oculatezza.
Una volta individuate le regioni di codice che occupano maggiore tempo di
esecuzione si può passare alla fase di ottimizzazione vera e propria.
1.1 - Tre "livelli" di ottimizzazione
Solitamente, il processo di ottimizzazione si
articola in due o al più tre fasi.
La prima è l'ottimizzazione "ad alto livello", ovvero
l'ottimizzazione algoritmica. In questa fase si va alla ricerca di un algoritmo
più efficiente rispetto a quello correntemente utilizzato, senza però
pregiudicare i risultati. Ad esempio, se è necessario un algoritmo di
ordinamento (sort) si può considerare la possibilità di passare dal bubble
sort al più complesso ma decisamente più performante quick sort.
La seconda fase riguarda l'implementazione dell'algoritmo. A volte, infatti, si
possono ottenere risultati soddisfacenti con un algoritmo differente (anche dal
punto di vista funzionale) ma che assicurerà comunque all'utente finale il
raggiungimento dell'obiettivo preposto.
La terza e ultima fase è l'ottimizzazione "a basso livello". E' qui
che i programmatori in linguaggio assembly fanno la differenza. Le tecniche
utilizzate in questa fase sono molteplici: l'uso di istruzioni più veloci, loop
unrolling, efficiente utilizzo della cache e delle altre risorse di cui è
dotato il processore, e così via. Ovviamente questa fase dell'ottimizzazione
può essere complessa e diminuire notevolmente la leggibilità del codice,
pertanto va considerata come ultima spiaggia e messa in atto solo dopo avere la
certezza di non poter più ottimizzare secondo i primi due "livelli".
Per essere in grado di ottimizzare a questo livello sono necessarie conoscenze
approfondite del processore e del suo funzionamento architetturale. Iniziamo
quindi con uno studio delle componenti hardware atte a raggiungere prestazioni
più elevate nella velocità di esecuzione delle istruzioni.
Idealmente, l'operato del processore si potrebbe riassumere così:
In realtà, un funzionamento schematico di
questo tipo non permette il raggiungimento di prestazioni elevate. E' per questo
che nel corso del tempo sono state ideate strategie allo scopo di ottenere
risultati più soddisfacenti: pipeline, memoria cache, parallelismo
nell'esecuzione delle istruzioni, tecnologie SIMD, etc.
Iniziamo con un'analisi del funzionamento della pipeline.
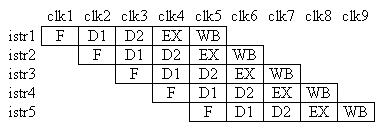
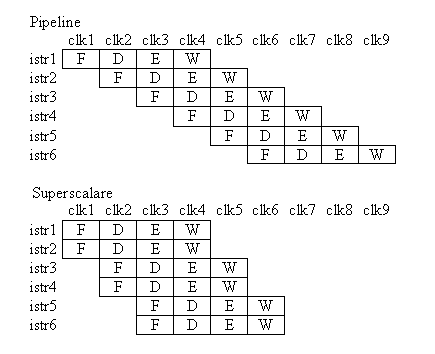
Una delle tecniche implementative più importanti presenti nei processori è costituita dalla pipeline. Nella serie x86 di processori questa tecnica fu adottata per la prima volta negli Intel 486. Il principio di base è molto semplice: dato che in generale l'esecuzione delle istruzioni si può suddividere in diversi stadi, mentre uno stadio della pipeline lavora con un'istruzione, lo stadio precedente può già lavorare con l'istruzione successiva. In questo modo si possono teoricamente eseguire le istruzioni con una velocità maggiore, o più precisamente (assumendo che tutti gli stadi siano indipendenti e abbiano la stessa durata) se n è il numero di stadi la velocità sarà n volte maggiore rispetto ad un'esecuzione sequenziale: si cerca di raggiungere un throughput di 1 istruzione per ciclo di clock. Tipicamente, le istruzioni si possono ricondurre a 5 stadi (possono riscontrarsi differenze tra varie architetture o anche tra processori differenti della stessa famiglia; utilizziamo a titolo di esempio la pipeline dei processori Intel Pentium):
Il processore inizia la fase F della prima istruzione; poi passa alla fase D1 e una seconda istruzione inizia la fase F; la prima istruzione va quindi allo stadio D2 mentre la seconda arriva allo stadio D1 e una terza istruzione inizia il Fetch, e così via. Dopo al più 5 istruzioni si raggiungono le condizioni ideali (5 volte più veloce dell'esecuzione sequenziale):
In questa figura ogni riga rappresenta un'istruzione e ogni colonna un ciclo di clock. Si ipotizza che ogni stadio abbia la durata di un ciclo di clock. In questo modo riusciamo ad eseguire 5 istruzioni in soli 9 cicli di clock, contro i 5*5=25 (numero di stadi * numero di istruzioni) cicli che ci sarebbero serviti con un'esecuzione sequenziale: con la pipeline abbiamo eseguito le stesse istruzioni 25/9 = 2,8 volte più velocemente. Ovviamente non abbiamo ottenuto il miglioramento di 5 volte che avevamo ipotizzato perché abbiamo considerato un numero molto limitato di istruzioni. Ripetendo il calcolo con, ad esempio, 10000 istruzioni, otteniamo 10000 * 5 = 50000 clocks per l'esecuzione sequenziale; l'esecuzione mediante pipeline richiede invece 5 clocks (ovvero il tempo per completare la prima istruzione) per raggiungere le condizioni ideali e poi riesce ad eseguire 1 istruzione per ciclo di clock, quindi in totale avremo 5 + (10000-1) clocks, cioè 10004: abbiamo perciò ottenuto un miglioramento pari a 50000/10004 = 4,998 volte. Se poi si considera che i moderni processori eseguono milioni di istruzioni ogni secondo, si capisce quanto sia efficiente il progetto tramite pipeline.
Tornando all'esempio precedente, abbiamo visto che il processore raggiunge (almeno in linea teorica) un' efficienza 5 volte maggiore dell'esecuzione sequenziale. Potremmo quindi dire che il processore esegue le istruzioni ad una velocità 5 volte maggiore? No. Infatti ogni istruzione richiede ugualmente 5 cicli di clock per essere completata. L'aumento della velocità è dovuto al parallelismo con cui le istruzioni vengono eseguite: in condizioni ideali, il processore riesce ad elaborare 5 istruzioni contemporaneamente, consentendo, di fatto, il raggiungimento di velocità di esecuzione effettive 5 volte maggiori. Bisogna quindi fare la distinzione tra il throughput e la latenza delle istruzioni.
La latenza è la durata
effettiva di ogni singola istruzione, contando tutti i cicli di clock necessari
al suo completamento.
Il throughput è la durata pratica dell'istruzione, o, in altre parole,
la velocità con cui le istruzioni vengono completate (indipendentemente dalla
latenza effettiva).
E' chiaro che l'obiettivo primario dell'ottimizzazione è quello di aumentare al
massimo il throughput; è comunque utile in genere ridurre la latenza
quando possibile, dato che ciò porta spesso ad un miglioramento del throughput.
2.1.2 Il problema degli stalli
Abbiamo visto che il sistema della
pipeline può potenzialmente raggiungere un throughput di 1 istruzione per ogni
ciclo di clock. In realtà possono sorgere parecchi problemi che costringono il
processore a fermarsi per uno o anche più cicli. Tali condizioni sono
definite criticità o stalli.
Si distinguono tre tipi di criticità: strutturali, sul controllo e sui dati.
Le criticità strutturali sono quelle situazioni in cui il processore è costretto ad entrare in stallo perché non dispone delle risorse hardware necessarie ad eseguire una determinata combinazione di istruzioni. Ad esempio, se un processore non può effettuare più di una lettura dalla memoria contemporaneamente e abbiamo nella pipeline quattro istruzioni, la prima delle quali accede alla memoria nel quarto stadio (EX), la quarta istruzione subirà uno stallo di un clock in quanto deve ritardare il Fetch (che richiede un accesso alla memoria).
2.1.2.2 Criticità sul controllo
Le criticità sul controllo sono
uno dei problemi cui si deve prestare maggiore attenzione nell'ottimizzazione di
codice, soprattutto per i processori più recenti.
Quando un processore incontra un'istruzione di salto condizionale, non può
sapere in anticipo se il salto verrà effettuato o meno. Dovrà quindi provocare
uno stallo nell'attesa di decidere l'esito del salto:
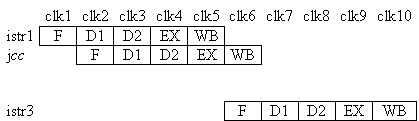
La figura
mostra il comportamento della pipeline in presenza di un salto condizionale (indicato
con jcc). L'esito del salto dipende dall'istr1, quindi prima di sapere se
il salto verrà eseguito o meno e iniziare il fetching dell'istruzione
successiva al salto è necessario completare lo stadio EX del salto stesso,
inserendo uno stallo (in questo esempio pari a 3 cicli di clock). E' chiaro che
con un maggior numero di stadi nella pipeline cresce proporzionalmente l'entità
dello stallo. I processori più recenti hanno spesso pipeline molto lunghe, ed
è per questo che l'efficiente implementazione delle istruzioni di salto è
considerata l'ottimizzazione più importante.
Vedremo dopo come i processori possono ridurre e talvolta eliminare gli stalli
in queste situazioni.
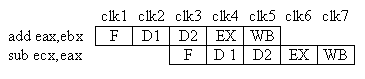
Le criticità sui dati sono quelle situazioni in cui la pipeline è costretta ad entrare in stallo perché non dispone dei dati necessari ad eseguire un'istruzione. Ad esempio:
add eax,ebx
sub ecx,eax
In questo esempio abbiamo una criticità sui dati perché l'istruzione sub utilizza il registro eax che è stato scritto nell'istruzione precedente; in queste condizioni il processore è costretto ad inserire uno stallo perché il risultato dell'istruzione add viene salvato nel registro eax solo nel quinto stadio (WriteBack), mentre l'istruzione sub ne ha bisogno nel quarto stadio (EX):
Vediamo adesso come i processori possano risolvere i vari tipi di criticità.
2.1.2.4 Eliminazione delle criticità
Criticità strutturali
Le criticità strutturali sono, come abbiamo visto, legate ad un'insufficiente disponibilità di risorse hardware. Per risolvere questo tipo di problemi è in genere sufficiente aumentare tali risorse, ad esempio implementando due write buffer anziché uno. Per le criticità strutturali relative all'accesso alla memoria è poi importantissimo l'uso della cache, di cui vedremo dopo il funzionamento e le caratteristiche generali.
Criticità sul controllo
L'eliminazione o comunque la riduzione delle criticità sul controllo influiscono enormemente sulle prestazioni raggiungibili dal processore. E' per questo che nel corso del tempo si sono sviluppate tecnologie sempre più sofisticate per la soluzione del problema.
L'introduzione degli stalli è,
chiaramente, conservativa ma poco efficace. I processori utilizzano quindi delle
tecniche di predizione del salto, o branch prediction.
Il tipo più semplice di branch prediction è l'assunzione da parte del
processore che un salto non venga mai eseguito. In questo modo se la predizione
si rivela corretta il processore non subirà nessuno stallo. Se invece la
predizione è sbagliata è necessario annullare tutte le operazioni effettuate
dal momento del salto in poi (incorrendo ovviamente in uno stallo).
Un approccio un po' più sofisticato consiste nel predire che alcuni salti siano
effettuati e altri no: in genere si predicono come taken i salti che
puntano ad una locazione di codice precedente al salto (backward branch)
e come not taken quelli che puntano ad una locazione successiva (forward
branch). Ciò è in genere piuttosto efficiente in quanto tra i backward
branch vi sono quelli che saltano all'inizio di un loop o altro tipo di
procedure iterative, e quindi saranno effettivamente eseguiti il più delle
volte. Durante la scrittura del codice è sempre necessario tenere presente
questo tipo di predizione e, se possibile, usare backward branches per i salti
che saranno
eseguiti con una probabilità superiore al 50% e forward branches se la
probabilità è inferiore al 50%.
Questi algoritmi analizzati finora
sono detti di predizione statica (static branch prediction). La grande
efficienza della predizione nei processori più recenti è dovuta ad algoritmi
di predizione dinamica (dinamic branch prediction). Questo tipo di
predizione non segue rigidi schemi come per la predizione statica, ma utilizza
le informazioni sui salti accumulate durante l'esecuzione del codice. Pertanto,
se ad esempio il processore "ricorda" che un determinato backward branch non ha
mai saltato, può predirlo come not taken nonostante la predizione
statica suggerisca il contrario.
L'evoluzione della predizione dinamica (che analizzeremo approfonditamente in
seguito) ha consentito di raggiungere un'efficienza nella predizione pari anche
al 95%. Ovviamente per il raggiungimento di queste alte percentuali è
necessaria una buona ottimizzazione del codice assembly da parte dei compilatori
e, non di meno, dei programmatori.
Criticità sui dati
Anche le criticità sui dati sarebbero molto gravi se non si prendessero delle contromisure. Una prima soluzione è quella di interporre delle istruzioni non dipendenti tra le due istruzioni che provocano la criticità. Ciò è comunque in genere poco efficiente, in quanto queste dipendenze di dati sono molto frequenti e gli stalli (specie in pipeline molto lunghe) possono raggiungere entità notevoli. Non è quindi sempre possibile per i programmatori (e tanto meno per i compilatori) risolvere facilmente il problema. I processori devono quindi dare il loro giusto contributo con l'implementazione di circuiti particolari che permettano di eliminare, quando possibile, le dipendenze. Torniamo all'esempio visto prima:
add eax,ebx
sub ecx,eax
Abbiamo visto che il risultato viene salvato in eax solo dopo il quinto stadio (WB). Tuttavia, notiamo che esso è già disponibile dopo il quarto stadio (EX). Intervengono quindi dei circuiti appositi che prelevano il risultato dalla pipeline e lo passano all'istruzione successiva prima ancora di effettuare il writeback. Questo meccanismo è definito propagazione. In questo modo lo stallo può essere completamente assorbito:
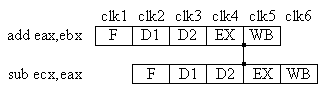
Nella figura la linea verticale simboleggia la propagazione del risultato dello stadio EX dell'istruzione add al medesimo stadio (che necessita del risultato come dato di ingresso) dell'istruzione sub, permettendo così l'esecuzione sequenziale senza l'introduzione di stalli.
Nel corso del tempo la velocità
dei processori è andata via via aumentando, passando da frequenze di pochi
megahertz (Mhz) a quelle attuali che si misurano ormai in gigahertz.
Tuttavia non vi è stato un uguale sviluppo di velocità per le memorie RAM. La
costruzione di memorie veloci è infatti molto costosa e i chip risultanti sono
in genere troppo ingombranti per le richieste di dimensioni della tecnologia
attuale. La necessità di mediare fra l'efficienza e i costi di produzione e le
necessità tecniche ha portato all'implementazione della memoria cache.
La cache è una memoria volatile (al pari della RAM) generalmente di dimensioni
relativamente piccole ma con la caratteristica di essere molto veloce. Essa
viene utilizzata come "intermediario" tra la lenta memoria RAM e il
processore. Quando la CPU necessita di accedere ad un determinato indirizzo in
memoria, esso viene caricato nella cache in maniera tale che i successivi
accessi siano molto più rapidi. Tuttavia non viene caricata nella cache solo la
word (intesa come dimensione di dati standard del processore, ovvero 32
bit negli attuali processori) richiesta, ma un'intera cache line, costituita da più word
(negli attuali processori si hanno word di 32 bit (= 4 byte) e cacheline di 32
byte, cioè 8 word).
Ciò potrebbe sembrare poco efficiente: caricare un'intera linea composta da
molte word quando è necessario leggere solo una dato dalla memoria appare
piuttosto insensato. L'architettura della cache si basa sul principio della localizzazione:
durante l'esecuzione, il processore non accede ad indirizzi di memoria casuali,
ma tutti i dati utilizzati dal processore si trovano in genere vicini tra loro.
In questo modo, con un solo cache line fill (riempimento di una linea) si
può accedere a un gran numero di dati in memoria ad un costo (in termini di
cicli di clock) molto limitato.
I primi PC ad adottare il sistema della cache furono gli Intel 80386, in cui però la cache era facoltativa e integrata solo in alcune motherboard. Era ancora relativamente lenta e piccola (soli 8 kb), e implementava il sistema write-through; in seguito circolarono anche caches più veloci e più grandi (fino a 128 kb) con il sistema write-back (parleremo di write-through e write-back nei paragrafi successivi). Negli Intel 80486 e processori compatibili (come i "cloni" dei concorrenti AMD e Cyrix) la cache (inizialmente write-back di 8 kb) fu per la prima volta integrata nella CPU, permettendo, anche a parità di frequenza, risultati notevolmente maggiori rispetto agli 80386.
A partire dai processori Pentium si ebbe l'integrazione di due livelli di cache: i dati passano quindi, sempre con lo stesso meccanismo, dalla memoria centrale alla cache di secondo livello (2L), a quella di primo livello (1L), per arrivare alla CPU. Generalmente la cache di secondo livello ha grandi dimensioni, fatto che ha positive ripercussioni sulla velocità, specialmente in sistemi multitasking e motherboard multiprocessore.
L'hit rate rappresenta la percentuale (sul totale di accessi in memoria) di accessi risolti tramite la cache. E' chiaro che maggiore è l'hit rate, maggiore è l'efficienza della cache stessa.
Non è sempre facile dare una stima esatta dell'hit rate. Esso, infatti, dipende da molti fattori esterni, e in particolare dal tipo di codice che viene eseguito nella CPU. Compilatori differenti possono dare risultati differenti sullo stesso tipo di cache o essere ottimizzati per tipi di cache differenti. L'hit rate va quindi considerato come una stima molto approssimativa, e non come un dato assoluto.
A seconda di come la cache sia internamente strutturata se ne distinguono tre tipologie: cache a mappa diretta, cache completamente associativa, cache set-associativa.
Nella cache a mappa diretta (direct
mapped) ogni dato che deve essere messo nella cache può andare ad un solo
univoco blocco (un blocco è un insieme di dati che vanno nella cache
insieme, cioè una cacheline), calcolato come:
addr modulo N (NB: l'operatore "modulo"
indica il resto della divisione)
dove addr è il numero del blocco in considerazione (e NON l'offset) e N il numero di blocchi nella cache. Si dovrà comunque affiancare ad ogni blocco un TAG per identificare l'indirizzo effettivo, dato che ogni blocco può contenere dati ad indirizzi diversi. Ad esempio, se si dispone di una RAM di 64 Mb e una cache di 256 Kb a blocchi di 32 byte. Il numero di blocchi della RAM sarà quindi 64 * 2^20 / 32 = 2097152, mentre il numero di blocchi della cache è dato da 256 * 2^10 / 32 = 8192. Ogni blocco dovrà quindi coprire un numero di indirizzi pari a 2097152 / 8192 = 256. E' chiaro che un'implementazione di questo tipo, pur essendo piuttosto semplice sia concettualmente sia da un punto di vista della realizzazione pratica, porta con sé un grosso problema: due indirizzi uguali in modulo N (ad esempio due indirizzi multipli di N) non potranno mai essere contenuti contemporaneamente nella cache. Proprio questo tipo di conflitti, tutt'altro che rari, rappresenta il più grosso limite di un sistema di cache così poco flessibile.
2.2.3 - Cache completamente associativa
La cache completamente associativa
(fully associative) è concettualmente opposta a quella a mappa diretta.
Se nella cache a mappa diretta ogni indirizzo andrà in un blocco univoco e
facilmente identificabile, nella cache fully associative ogni blocco può
contenere dati situati in qualunque indirizzo in memoria.
Questo tipo di cache garantisce normalmente un hit rate superiore rispetto alla
cache direct mapped, ma porta parecchi problemi tecnici. Ogni blocco dovrà
infatti essere affiancato ad un TAG che identifica l'indirizzo del dato
contenuto, e poiché ogni blocco può contenere dati da qualunque indirizzo si
avranno TAG molto grandi, con conseguenze sui costi del sistema. Inoltre, ad
ogni accesso in memoria, si dovrà controllare l'eventuale presenza del dato
richiesto in ogni blocco, basandosi sul TAG. Questo controllo può essere fatto
in parallelo, ma richiede circuiti aggiuntivi che incrementano ancora i costi e
comunque peggiorano le prestazioni della cache.
E' per questo che il sistema della cache completamente associativa non ha
trovato larga diffusione, se non per cache di dimensioni molto piccole. Si sono
invece diffusi dei sistemi che mediano tra la flessibilità della cache
associativa e la semplicità concettuale e pratica della cache a mappa diretta:
le cache set-associative.
Le cache set-associative, o associative ad insiemi, sono come abbiamo detto un sistema intermedio tra gli atri due sistemi. La cache è divisa in un certo numero S di insiemi (o set), e ogni insieme è costituito da un certo numero di blocchi. Se il numero di blocchi per ogni insieme è N, si parla di N-way set-associative cache (cache associativa a N insiemi). Abbiamo visto che nella cache a mappa diretta il blocco di destinazione era dato da:
addr modulo N dove addr è il numero del blocco ed N il numero di blocchi della cache
In una cache N-way set-associative possiamo calcolare solo in quale insieme della cache andrà un blocco di dati ad un determinato indirizzo:
addr modulo S dove addr è il numero del blocco ed S il numero di insiemi della cache.
All'interno dell'insieme, non
sappiamo invece dov'è situato il nostro dato. In questo modo, un qualunque
indirizzo può essere affidato ad N blocchi distinti, ed al momento di
effettuare una lettura o una scrittura il processore dovrà controllare la
presenza del dato solo in questi N blocchi.
Per stabilire in quale blocco di un insieme andranno i dati che dobbiamo
caricare nella cache si utilizza in genere un algoritmo LRU (Least Recently Used): i dati prenderanno il posto del blocco che non viene usato da maggior
tempo, in maniera tale che nella cache restino solo i dati usati più di
recente, ovvero, in genere, quelli con cui si sta lavorando.
Il numero di insiemi della cache è ovviamente dato da:
(numero di blocchi) / N
Quindi ad esempio una cache 4-way set-associative con 256 blocchi avrà 256/4 = 64 insiemi.
Facciamo un esempio con i vari
sistemi tanto per chiarire le idee. Supponiamo di avere un dato al blocco numero
18 e una cache di 8 blocchi.
Con il sistema direct mapped l'indirizzo di destinazione del blocco nella cache
sarà
18 modulo 8 = 2.
Il processore dovrà quindi cercare la presenza del dato richiesto SOLO nel
blocco numero 2.
Con una cache fully-associative il processore deve ricercare il dato richiesto
in tutti i 18 blocchi, in quanto non può sapere in quale blocco il dato possa
essere contenuto.
Con una cache 2-way set-associative, avremo 8/2 = 4 insiemi. Il dato, se
presente nella cache, andrà nell'insieme 18 modulo 4 = 2. Il processore dovrà
quindi limitarsi a cercare ed eventualmente caricare il dato richiesto in
entrambi i blocchi dell'insieme numero 2 (NB: il primo insieme è l'insieme 0,
quindi se abbiamo n insiemi essi avranno indici 0, 1, 2,..., n; l'insieme numero 2
è dunque il terzo e non il secondo della cache).
2.2.5 - Strategia write-through
Quando il processore accede in scrittura ad un dato presente della cache, si può procedere in due modi.
Le cache write-through prevedono che la scrittura avvenga contemporaneamente nella cache e nella memoria centrale. Ciò assicura la coerenza dei dati, ma una scrittura in memoria è molto più lenta di una scrittura nella cache, pertanto un sistema di questo tipo non riesce in genere a garantire ottime prestazioni. Per questo si opta in genere per cache con sistema write-back.
Diversamente dal metodo
write-through in cui la cache è trasparente alle scritture, nel sistema
write-back queste vengono effettuate solo nella cache, e l'aggiornamento della
memoria centrale avviene solo quando una cacheline deve essere occupata da altri
dati o si ha la necessità di mantenere la coerenza.
In questo modo l'aggiornamento della memoria centrale avviene solo quando è
indispensabile, con un notevole aumento delle prestazioni in scrittura.
Abbiamo visto che l'adozione di architetture basate sulla pipeline mira al raggiungimento di 1 istruzione per ciclo di clock. Per migliorare ulteriormente le prestazioni, oltre ad aumentare al massimo la frequenza di ogni ciclo di clock (cioè la velocità in megahertz), non resta che l'implementazione del parallelismo: il processore dovrà quindi essere in grado di elaborare più istruzioni contemporaneamente. Di fatto anche la pipeline consente l'esecuzione in parallelo di più istruzioni. Tuttavia, le istruzioni sono suddivise in stadi, e ogni stadio elabora una sola istruzione. I processori più recenti utilizzano tecniche avanzate che consentono un parallelismo ancora più efficiente: architetture superscalari, architetture superpipeline ed esecuzione out-of-order.
2.3.1 - Architetture superscalari
Sono detti superscalari quei processori che possono caricare ed eseguire indipendentemente più di un'istruzione per ciclo di clock. In particolare, un processore superscalare di grado n può eseguire contemporaneamente un massimo di n istruzioni (utilizzo, per semplicità delle figure, pipeline di soli quattro stadi: Fetch, Decode, Execute, Writeback; ovviamente il principio è lo stesso per pipeline di lunghezza diversa):
Potenzialmente, un processore superscalare di grado n può essere n volte più veloce. Notate che in una pipeline normale si ha l'elaborazione contemporanea di un numero di istruzioni pari al numero di stadi, ma in ogni stadio è presente una sola istruzione in elaborazione. Nei processori superscalari, invece, ogni stadio lavora contemporaneamente a n istruzioni diverse. E' chiaro che per consentire un'implementazione di questo tipo è necessario aumentare le risorse hardware, per evitare di incorrere in criticità strutturali.
2.3.2 - Architetture superpipeline
I processori superpipeline possono iniziare l'esecuzione di una sola istruzione per ogni ciclo di clock. Quello che cambia è la frequenza del ciclo di clock: essa viene infatti diminuita, pur mantenendo invariata la latenza di ogni stadio. Le operazioni compiute dagli stadi vengono quindi divise in due o più operazioni, che vengono "sovrapposte" come in una pipeline normale si sovrappongono gli stadi:
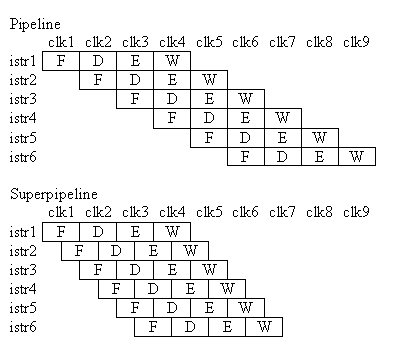
In questo modo, ogni ciclo di clock avrà durata 1/n e ogni stadio della pipeline sarà formato da n "sotto-operazioni"; chiaramente in questo modo la latenza di ogni stadio non cambia, ma il throughput aumenta n volte.
Ovviamente si possono progettare anche dei processori superscalari superpipeline:
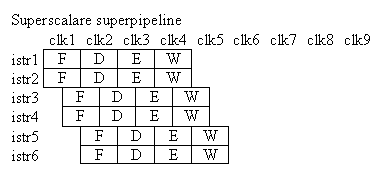
Ovviamente l'aumento del parallelismo incrementa notevolmente le prestazioni, ma incrementa la probabilità di stalli dovuti a dipendenze tra le istruzioni. Si distinguono 5 tipi di dipendenze, che analizzeremo singolarmente.
Le dipendenze strutturali si verificano quando due istruzioni richiedono l'uso della stessa risorsa hardware (vedi paragrafi 2.1.2.1 e 2.1.2.4).
Le dipendenze sul controllo sono dovute alla presenza di un'istruzione di salto che modifica il flusso del programma (vedi paragrafi 2.1.2.2 e 2.1.2.4).
Le dipendenze di uscita
(o di scrittura-scrittura) avvengono quando due istruzioni modificano la stessa variabile (generalmente un
registro) che viene poi eventualmente utilizzata da istruzioni successive.
Es:
mov eax, ebx
add eax, ecx
Le antidipendenze o dipendenze
di lettura-scrittura avvengono quando un'istruzione scrive su una variabile
letta nell'istruzione precedente. Queste dipendenze possono comunque essere
risolte senza provocare stalli grazie a tecniche come il renaming, che
vedremo dopo.
Es:
mov ebx,eax
xor eax,eax
2.3.4 - Esecuzione out-of-order
Un'altra tecnica che i moderni
processori adottano per aumentare il grado di parallelismo è l'esecuzione
out-of-order, che si contrappone al sistema in-order, ossia sequenziale.
In questo tipo di implementazioni la pipeline è divisa in diverse unità,
alcune in-order e altre out-of-order. Esistono diverse strategie di esecuzione:
- Inizio in-order e completamento
in-order, il metodo più vecchio e ovviamente poco performante a causa delle
dipendenze.
- Inizio in-order e completamento out-of-order. In questo caso le istruzioni,
pur iniziando sequenzialmente, possono "superare" un'istruzione
successiva con maggiore latenza (eventualmente rallentata da uno stallo). In
questo modo si ha una diminuzione degli stalli dovuti alle dipendenze.
- Inizio out-of-order e completamento out-of-order. Questa strategia è la più
sofisticata e di gran lunga la più efficiente. Dopo la decodifica (che si
occupa anche, se necessario, di scomporre le istruzioni in operazioni semplici)
le istruzioni vengono inserite in un buffer (chiamato Instruction Window);
l'execution unit controlla quali istruzioni siano pronte per l'esecuzione
(ovvero prive di dipendenze, che implica la disponibilità di dati e risorse
hardware), indipendentemente dall'ordine originario del programma. In questo
modo, mentre un'istruzione è ritardata a causa di uno stallo o di eccessiva
latenza, le istruzioni che lo seguono possono comunque essere eseguite a patto
di essere prive di dipendenze. Dopo l'esecuzione out-of-order, si devono salvare
i risultati, e ciò deve ovviamente essere fatto in-order per motivi di coerenza
semantica.
2.3.5 - Renaming
Una tecnica utilizzata nei processori superscalari per eliminare (quando è possibile) le dipendenze è il rinomina dei registri (register renaming). Per permettere questa tecnica il processore deve disporre di un numero di registri fisici maggiore rispetto ai registri accessibili al programmatore. Ogni volta che il processore incontra un'operazione di caricamento su un registro crea un nuovo registro temporaneo, preservando il vecchio valore del registro. Facciamo un esempio:
mov ebx,eax
add eax,5
Tra queste due istruzioni esiste un'antidipendenza. Nei processori superscalari (tanto più se out-of-order) è possibile che l'istruzione add venga eseguita contemporaneamente o anche prima dell'istruzione mov. Ciò potrebbe sembrare scorretto da un punto di vista semantico, in quanto add modifica il registro eax, necessario come input nell'istruzione mov. Per mantenere la correttezza semantica il processore crea una "copia" di eax e l'istruzione add non modifica la vecchia immagine del registro. Di fatto, potremmo così interpretare il codice:
mov ebx2,eax1
add eax2,5
Notiamo che anche l'istruzione mov crea un registro temporaneo (duplicato da ebx), che in questo caso non viene utilizzato.
Tramite il renaming si possono risolvere le dipendenze di scrittura-scrittura (dipendenze di uscita) e quelle di lettura-scrittura (antidipendenze).
NB: se un'istruzione accede sia in lettura che in scrittura ad un registro scritto nell'istruzione precedente, si ha una dipendenza di scrittura-lettura che non può essere risolta con il renaming. Esempio:
mov eax,1 ;scrittura
su eax
inc eax ;lettura-scrittura su eax (avviene il
renaming ma ciò non elimina la dipendenza)
2.3.6 - Esecuzione speculativa
L'esecuzione speculativa è fortemente legata ai meccanismi di branch prediction, cui tipicamente essa è applicata. Quando il processore incontra un'istruzione di salto non può sapere in anticipo se il salto sarà effettuato o meno. Pertanto deve ricorrere ai meccanismi di branch prediction e continua l'esecuzione del codice che si prevede seguirà il salto. Analogamente, se un'istruzione può fornire due risultati diversi in base ad una condizione (ad esempio l'istruzione setcc dell'architettura Intel) il processore effettua una previsione sulla condizione e calcola speculativamente il risultato dell'istruzione. Ovviamente il processore non salva immediatamente i risultati delle istruzioni eseguite speculativamente, in maniera tale che se la previsione si rivela errata si possano annullare tutte le operazioni effettuate.
3 - Famiglia di processori Intel
Dopo questa lunga ma dovuta introduzione
teorica, passiamo ad un'analisi più specifica delle architetture e
microarchitetture dei processori Intel, e delle conseguenti tecniche di
ottimizzazione.
Molte delle considerazioni che faremo sono valide anche per le architetture
compatibili (come i processori AMD corrispondenti), mentre alcune sono
specifiche per singoli processori.
Per semplicità utilizzeremo le seguenti abbreviazioni:
| Abbreviazione | Nome |
| PPlain | Plain old Pentium (senza estensioni MMX) |
| PMMX | Pentium con MMX |
| PPro | Pentium Pro |
| PII | Pentium II |
| PIII | Pentium III |
| P4 | Pentium 4 |
Iniziamo con una breve descrizione delle varie microarchitetture, per ognuna delle quali approfondiremo in seguito i dettagli che ci interessano.
Il processore Pentium è superscalare, basato
su due pipeline generiche e una pipeline per le istruzioni floating point; il
processore può quindi eseguire due istruzioni contemporaneamente.
La due pipeline (chiamate rispettivamente U-pipe e V-pipe) sono strutturalmente
simili, ma la seconda (V) ha delle limitazioni sulle istruzioni che può
eseguire. Ognuna di queste pipeline è suddivisa in 5 stadi:
PF - Prefetch
D1 - Decode stage 1
D2 - Decode stage 2
E - Execute
WB - Writeback
Con questo sistema superscalare il processore
può, come abbiamo già detto, eseguire fino a due istruzioni
contemporaneamente. Durante l'esecuzione, il processore controlla che le
successive due istruzioni siano pronte per l'esecuzione e non abbiano
dipendenze, e, quando possibile, prepara l'esecuzione delle due istruzioni
successive (una nella U-pipe e una nella V-pipe); quando invece ciò non è
possibile il processore esegue solo un'istruzione nella U-pipe (e la V-pipe non
viene utilizzata). Ovviamente l'esecuzione contemporanea non compromette la
correttezza dell'esecuzione, mantenendo la coerenza dei risultati con
l'esecuzione sequenziale.
Vedremo in seguito alcuni dettagli sulla pipeline e sulle conseguenti
ottimizzazioni del codice.
I processori Pentium sono dotati di cache integrata pari a 8 kb per il codice e 8 kb per i dati. L'implementazione è 2-way set-associative e la dimensione di una cacheline è pari a 32 bytes. Entrambe le caches utilizzano un algoritmo di sostituzione LRU (Least Recently Used, di cui abbiamo già parlato nel paragrafo sulle cache set-associative). Le due pipeline possono accedere alla cache contemporaneamente, a patto che i due accessi avvengano in cache-banks differenti, ovvero che i bit 2-4 non siano uguali nei due indirizzi, o, in altri termini, che (assumendo il corretto allineamento dei due indirizzi) la differenza fra i due indirizzi non sia divisibile per 32.
Il processore Pentium dispone di un Branch
Target Buffer (BTB) di 256 entry per i meccanismi di branch prediction (una
previsione errata provoca uno stallo di 3 clock se il salto viene eseguito nella
U-pipe, 4 clock nella V-pipe).
Il prefetch avviene (ovviamente nello stadio PF) grazie a quattro prefetch
buffer di 32 byte ciascuno, che lavorano a due a due (in questo modo è
possibile il prefetch di istruzioni che iniziano in un blocco di 32 bytes e
terminano nel blocco successivo, senza la necessità di introdurre stalli). I
prefetch buffer sono strettamente collegati al BTB: quando si incontra
un'istruzione di salto, lo stadio di PF richiede una previsione al BTB. Se il
salto è previsto come not taken il prefetch continua normalmente; se
invece è previsto come taken viene attivata la seconda coppia di
prefetch buffer che inizia il prefetch della destinazione del salto. In caso di
predizione errata, come al solito, si ripulisce la pipeline e si ricomincia
tutto dall'inizio.
Altra caratteristica microarchitetturale importante sono i due write buffer di 64 bit (8 bytes) ciascuno. Ad essi si può accedere contemporaneamente (nel caso di un cache miss in scrittura nella U-pipe e uno nella V-pipe in due istruzioni eseguite contemporaneamente, condizione questa definita pairing). In questo modo il processore può continuare l'esecuzione senza aspettare di completare la scrittura, tranne ovviamente quando le istruzioni successive dipendono dal risultato della scrittura, condizione comunque che spesso può essere facilmente risolta con una migliore organizzazione del codice.
L'unità floating point integrata al processore aggiunge tre stadi alla pipeline delle istruzioni intere. L'esecuzione prosegue normalmente fino allo stadio E, prima di eseguire il quale passa ai tre stadi della pipeline floating point (X1, X2 e WF). Lo stadio WB non viene eseguito nella pipeline FPU. Molte istruzioni floating point hanno latenze piuttosto lunghe (maggiori di 1 clock), che possono spesso essere nascoste dall'esecuzione in parallelo (e in pipeline) di altre istruzioni. L'istruzione FXCH (che scambia due registri dell'unità FPU) può essere eseguita in parallelo con le istruzioni FPU più comuni, permettendo di scambiare due registri senza nessun costo (o quasi) in termini di velocità di esecuzione e, di fatto, di trattare i registri FPU (organizzati come uno stack) come una normale batteria di registri.
La tecnologia MMX è la prima implementazione
nell'architettura dei processori Intel che sfrutta tecniche SIMD (Single
Instruction, Multiple Data) per permettere il parallelismo durante la
manipolazione dei dati.
Da un punto di vista architetturale si sono rese necessarie diverse
modificazioni: l'aggiunta di 8 registri (da MM0 a MM7) e un gran numero di nuove
istruzioni. Per maggiori informazioni sull'architettura MMX, consultare i
manuali Intel.
Anche da un punto di vista microarchitetturale sono stati necessari alcuni
adattamenti.
Lo stadio F è stato diviso in due: PF e F.
Durante lo stadio PF il processore effettua il prefetch prelevando le istruzioni
dalla code cache; nello stadio F avviene il parsing delle istruzioni e
l'eventuale decodifica dei prefissi (di cui parleremo dopo).
Tra gli stadi F e D1 è presente un buffer FIFO (First In First Out) che
contiene le istruzioni (fino ad un massimo di 4) da mandare allo stadio D1.
Quando il fetch è rallentato (ad esempio per uno stallo) il buffer FIFO si
svuota, ma ciò non comporta rallentamenti poiché, non essendo un vero stadio
della pipeline, non aggiunge latenza. Questo buffer può ricevere fino ad un
massimo di 2 istruzioni dallo stadio F. Poiché il throughput è mediamente
inferiore a 2 istruzioni per ciclo, difficilmente il buffer (o Instruction
FIFO) può arrivare a svuotarsi. In questo modo, l'Instruction FIFO può
gestire stalli durante il fetch o il parsing delle istruzioni (che possono
avvenire, ad esempio, quando la lunghezza delle istruzioni è eccessiva o sono
presenti prefissi).
La pipeline MMX è introdotta in maniera simile alla floating-point pipe. L'esecuzione prosegue normalmente fino allo stadio D2; per le istruzioni MMX si passa quindi agli stadi appropriati:
E/MR - Questo stadio svolge la lettura dalla
memoria per le istruzioni MMX.
Mex - Primo clock per l'unità multiplier (ovvero l'unità che esegue le
moltiplicazioni)
Wm/M2 - Per le istruzioni MMX di un ciclo di clock avviene il
writeback; esso è anche il secondo ciclo clock del multiplier.
M3 - Terzo ciclo del multiplier.
Wmul - Writeback per le istruzioni del multiplier.
Così come avviene per le istruzioni floating point, anche per le istruzioni MMX "salta" il ciclo WB, utilizzato solo dall'integer pipeline.
La cache integrata dei Pentium con tecnologia MMX è costituita da due caches 4-way set-associative di 16 kb ciascuna, con cacheline di 32 bytes. Entrambe le caches utilizzano la strategia writeback e algoritmi LRU. Entrambe le pipeline (U e V) possono accedere alla cache contemporaneamente, a condizione che i due accessi richiedano cache-banks differenti.
Il BTB e i meccanismi di branch prediction sono pressoché identici a quelli del Pentium Pro (vedi sotto).
Il processore dispone inoltre di 4 write buffer (contro i 2 del vecchio Pentium), ognuno dei quali può essere utilizzato da qualunque pipe (mentre nel Pentium senza MMX ad ogni pipe era associato un write buffer).
Il processore Pentium Pro è stato il primo
della famiglia Intel ad adottare avanzati sistemi di parallelismo come
l'esecuzione speculativa e l'out-of-order execution.
La pipeline è molto più complessa rispetto a quelle dei PPlain e PMMX; essa
può essere suddivisa in tre parti:
in-order front-end - Questa prima parte preleva le istruzioni nel loro ordine, effettua la decodifica dividendo ogni macro-istruzione in una o più micro-operations, o µops.
out-of-order core - La seconda parte della pipeline inizia con la Reservation Station (RS). In questo stadio ogni µop attende la disponibilità dei dati e delle risorse hardware, e successivamente viene inviato ad un'unità di esecuzione. Di fatto questo stadio effettua il riordinamento delle istruzioni.
in-order retirement unit - Dopo l'esecuzione ogni µop viene inviato al Re-Order Buffer (ROB), dove aspetta il retirement (ossia il salvataggio del risultato dell'esecuzione e, quindi, dello stato architetturale). Quest'ultima fase avviene ovviamente in-order per motivi di coerenza semantica.
La cache integrata di primo livello (L1) dei
processori Pentium Pro è costituita da una code cache di 8 kb e 4-way
set-associative, e una data cache di 8 kb e 2-way set-associative, entrambe con
cacheline di 32 bytes. Vi è poi una cache di secondo livello (L2) che può
nascondere un cache miss della L1 quando i dati si trovano nella L2.
Si può accedere contemporaneamente alla cache di dati per un load e uno store,
purché gli accessi richiedano cache-banks differenti.
La dimensione del BTB è stata raddoppiata (512 entry) e si sono notevolmente evoluti i meccanismi di branch prediction (con l'introduzione del pattern matching che vedremo dopo), nonché il prefetching, che deve essere tenuto in considerazione durante la fase di ottimizzazione del codice.
Il processore dispone di write buffers, e può effettuare il riordinamento degli accessi in memoria in base alle necessità, pur mantenendo, ovviamente, la coerenza semantica.
Il processore Pentium II ha una pipeline analoga a quella dei processori Pentium Pro, con in aggiunta il supporto per le estensioni MMX.
La cache integrata, il Branch Target Buffer e i write buffers presentano le stesse caratteristiche di quelli dei PMMX.
Il processore Pentium III è architetturalmente molto simile al suo predecessore PII, con l'unica notevole differenza delle SSE (Streaming SIMD Exstensions), che utilizza lo stesso principio delle estensioni MMX ma con registri a 128 bit.
I Pentium 4 sono i primi processori ad
utilizzare una nuova microarchitettura, chiamata Intel NetBurst. Sono state
apportate diverse migliorie rispetto ai predecessori, tra cui l'introduzione
delle estensioni SSE2 (ulteriore miglioramento delle SSE). Il processore è
altamente pipelined, e molte sue parti possono girare a velocità differenti a
seconda delle necessità, incrementando il clock rate medio. E' stato introdotto
anche l'hardware prefetch, che consente di prevenire la ripetizione di
cache miss, quando gli accessi in memoria avvengono secondo pattern ripetuti.
L'architettura di base è costituita dagli stessi componenti dei predecessori
(in-order front-end, out-of-order execution core, in-order retirement unit).
La cache integrata consiste in 2 livelli; il primo livello è formato da una data cache di 8 kb e 4-way set-associative, e una Trace Cache (per il codice) di 12K µops (12000 microistruzioni) e 8-way set-associative. La cacheline della cache L1 è di 64 bytes, anziché 32. La cache L2 è di 256 kb, 8-way set-associative, con una cacheline di 128 bytes.
Una profonda innovazione dei processori della serie dell'Intel Pentium 4 (per adesso utilizzata solo a livello server e non per i normali pc) è la tecnologia HyperThreading. Essa mira al raggiungimento di livelli di parallelismo impensabili in passato. Finora si sono utilizzate tecniche sempre più complesse e avanzate per migliorare l'Instruction Level Parallelism (ILP). La tecnologia HyperThreading mira invece al Thread Level Parallelism (TLP), che consente di eseguire due task contemporaneamente. Per far ciò nel processore molte strutture sono state duplicate, e di fatto si ottengono prestazioni simili a sistemi biprocessore. Per maggiori informazioni sull'architettura dei P4 e sull'HyperThreading, consultare i documenti indicati nella bibliografia, in particolare il [5] e il [9].
4 - Tecniche di ottimizzazione
Iniziamo finalmente a parlare, in maniera più pratica, delle varie tecniche di ottimizzazione a basso livello del codice. Le considerazioni riportate riguardano specificatamente i processori Intel IA32, sebbene generalmente valide anche per le CPU della concorrenza (ad esempio della AMD) che con essi sono compatibili.
Gli esempi di codice riportati utilizzano la sintassi del MASM (scaricabile dall'indirizzo www.movsd.com), anche se facilmente riadattabili per qualunque assembler.
Una regola fondamentale da osservare sempre, anche quando non ci si vuole addentrare più di tanto nel processo di ottimizzazione, è di mantenere il corretto allineamento dei dati. L'allineamento è ovviamente riferito all'indirizzo di memoria in cui i dati sono situati. In generale, bisogna seguire la seguente tabella:
| Dimensione: | Allineamento |
| 1 (byte) | 1 |
| 2 (word) | 2 |
| 4 (dword) | 4 |
| 6 (fword) | 8 |
| 8 (qword) | 8 |
| 10 (tbyte) | 16 |
| 16 (oword) | 16 |
In realtà, per quanto riguarda le fword e le oword, nei processori PPlain e PMMX è sufficiente allineare rispettivamente ad un multiplo di 4 e ad un multiplo di 8, ma ciò costerebbe un peggioramento delle prestazioni nei processori successivi, per cui è comunque consigliabile, per portabilità, seguire la tabella precedente.
Mentre i compilatori degni di questo nome allineano automaticamente le variabili, in assembler bisogna fare tutto manualmente (ed in fondo è per questo che l'assembler è bello :)). In MASM si può utilizzare la direttiva align seguita da un numero che sia una potenza di 2 (2, 4, 8 o 16); in alternativa si possono usare le seguenti diciture alternative, dall'ovvio significato:
align word ;allinea a multipli di 2
align dword ;allinea a multipli di 4
align qword ;allinea a multipli di 8
align oword ;allinea a multipli di 16
E' chiaro che se ad esempio si allinea per 4 una dword e le variabili successive sono tutte dword non è necessario utilizzare nuovamente la direttiva align:
.data? ;dati non inizializzati (è lo stesso
se usiamo .data, ovviamente)
align dword ;allinea per 4
dword1 dd ?
dword2 dd ?
dword3 dd ?
I segmenti sono per default allineati almeno a 16, quindi in questo caso la direttiva di allineamento poteva essere evitata, ma è sempre meglio esplicitare tutto, aumenta la chiarezza ed è più sicuro. Se aggiungessimo ad esempio la variabile byte1 di un solo byte all'inizio del segmento:
.data?
byte1 db ?
align dword
dword1 dd ?
dword2 dd ?
dword3 dd ?
Qui, se non avessimo messo la direttiva align dword, le tre dword successive non sarebbero state allineate, con la perdita di performance all'accesso che ne consegue. E' da notare che allineare i dati può comportare la perdita di qualche byte; ad esempio, nel codice appena visto si perderebbero 3 bytes, compresi tra le variabili byte1 e dword1, che resterebbero del tutto inutilizzati. Per chi come me non accetta di buon grado di sprecare bytes così, vi è comunque la possibilità di riordinare le variabili da quella di dimensione più grande a quella più piccola, facendo attenzione al fatto che se le variabili non sono potenze di 2 (ad esempio le fword che sono di 6 bytes) può essere auspicabile allineare ugualmente o mettere delle variabili di riempimento per riequilibrare l'allineamento... Un esempio chiarirà tutto:
.data?
align qword ;allinea per 8
qword1 dd ?
qword2 dd ?
fword1 df ? ;occupa 6 byte
word1 dw ? ;mettiamo una
variabile di 2 byte per riallineare ad 8
dword1 dd ?
dword2 dd
?
word2 dw ?
byte1
db ?
E' chiaro comunque che non è il caso di sconvolgere un eventuale ordine logico dei dati per risparmiare qualche byte... La leggibilità del codice potrebbe venirne compromessa, e ciò non è un pegno sufficiente per occupare un paio di bytes in meno. E' ragionevole sacrificare la leggibilità del codice per un miglioramento apprezzabile delle prestazioni.
I dati nello stack sono normalmente allineati per multipli di 4, dunque non è necessario nulla di particolare se le variabili sono di dimensione non superiore ad una dword. Nel caso in cui sia necessario avere la certezza di allineare correttamente dati più grandi per 8 o per 16 si può utilizzare codice come il seguente:
AlignedFunction proc
push ebp
mov ebp, esp
sub esp, SIZE_OF_LOCALSPACE
and esp, -8 ;allinea ad un indirizzo divisibile per 8
;se necessario, salva nello stack registri da preservare
...
;eventualmente ripristina i registri precedentemente salvati
nello stack
mov esp, ebp
pop ebp
ret
AlignedFunction endp
Dove con SIZE_OF_LOCALSPACE si intende ovviamente la dimensione dello spazio allocato per le variabili locali (necessariamente un multiplo di 4, aggiungendo qualche byte di padding, se necessario!). In questo modo utilizziamo ebp per accedere ai parametri della funzione ed ebp per accedere alle variabili locali. Attenzione!! E' chiaro che se esp viene modificato nel corso della funzione (ad esempio con istruzioni di push/pop) bisogna stare attenti a non sbagliare locazione di memoria; inoltre bisogna essere certi che le subroutines chiamata nel corpo della funzione non modifichino esp quando è ancora necessario accedere alle variabili locali.
Ovviamente allineare in questo modo può servire solo quando ci sono determinate esigenze di velocità del codice, in particolare quando le variabili allineate per 8 vengono utilizzate un gran numero di volte (ad esempio all'interno di cicli); nel dubbio, allineare non fa mai male.
Parleremo in seguito, dopo aver parlato della fase di decoding delle istruzioni, di ciò che concerne le differenti modalità di allineamento del codice.
4.2 - Ottimizzazione dell'uso della cache
Gli accessi in memoria sono, dal punto di vista dell'ottimizzazione, quasi una palla al piede per i moderni processori. Infatti, mentre la velocità dei processori aumenta considerevolmente di anno in anno, i progressi nelle prestazioni della RAM sono decisamente più contenuti. Di qui la necessità di ottimizzare il tutto attraverso la veloce memoria cache, e va da sé che, sebbene la cache sia del tutto trasparente agli applicativi, va usata con oculatezza per ottimizzarne l'utilizzo.
Come già detto in precedenza, la cache può contenere blocchi di memoria della lunghezza di 32 bytes (o 64/128 nell'architettura Intel NetBurst), corrispondenti con indirizzi di memoria multipli, appunto, di 32 (o 64). Quando si accede ad un dato che non è presente all'interno della cache, esso viene caricata una cacheline intera. Quest'operazione è ovviamente dispendiosa per il processore: un accesso a dati assenti nella cache può impiegare circa 200 nanosecondi (o più se i dati non sono presenti neppure nella L2 cache), mentre se i dati devono essere prelevati semplicemente dalla cache vi si può accedere in un solo ciclo di clock.
Dato che i dati vengono caricati nella cache a
blocchi allineati di 32, è conveniente allineare, quando possibile, ogni
elemento di un array alla potenza di due più piccola che li possa contenere,
eventualmente aggiungendo qualche byte di padding. Ad esempio, se gli elementi
di un array sono formati da una struttura di 13 bytes, è logico sacrificare 3
bytes per arrivare a 16. In questo modo, i dati che vengono caricati insieme
vengono utilizzati insieme, e ciò consente in generale di migliorare l'hit
rate.
In linea di principio, è una buona regola fare in modo che i dati che vengono
utilizzati insieme si trovino in blocchi di memoria contigui; ad esempio, se un
ciclo di codice accede a 2 array in memoria, è spesso opportuno (specie se gli
array sono di grosse dimensioni) "condensare" i due array in un unico
array di strutture, cosicché da accedere ai dati in maniera sequenziale.
Come già detto, la cache dei processori x86 è 2-way oppure 4-way set-associative. All'interno della cache possono coesistere fino ad un massimo di 2 o 4 cachelines i cui indirizzi di base abbiano i bits 5-11 uguali. Se tutti e 4 i blocchi sono impegnati e se ne deve caricare un altro con il medesimo cache bank (ossia con i bits 5-11 uguali), viene eliminata la cacheline che non veniva utilizzata da maggior tempo e viene sostituita con quella nuova (LRU replacement, di cui abbiamo già parlato). Se però si accede dopo breve tempo ai dati che sono stati eliminati dalla cache, deve avvenire nuovamente la sostituzione (cache bank conflict), e così via. Ciò comporta un dispendio in termini di tempo decisamente non trascurabile. Il modo più semplice per evitare questi inconvenienti è quello di mettere tutti i dati del programma (o almeno quelli maggiormente utilizzati) in un blocco contiguo di memoria di dimensione non superiore a quella della cache. Ovviamente, quando ciò è possibile e non comporta di dover sacrificare gli allineamenti, è sempre utile ridurre le dimensioni dei dati in memoria; in particolare, se un array viene utilizzato solo dopo che un altro array non serve più, si può sovrascrivere il primo array per condividere la stessa area di memoria, che probabilmente è già nella cache.
Le variabili locali vengono tipicamente allocate nello stack; è una buona pratica perché è in generale molto probabile che i dati nello stack siano presenti nella cache. Ovviamente, quando ciò è possibile, l'ideale per le variabili temporanee è l'uso dei registri; il registro ebp è tipicamente utilizzato per la creazione dello stack-frame, ma nulla vieta di creare uno stack frame utilizzando solo esp (o non crearlo per niente, quando possibile) per liberare ebp per altri scopi.
Qualunque blocco di codice impiega molto meno tempo per l'esecuzione quando è ripetuto rispetto a quando è eseguito per la prima volta. Infatti, quando il codice viene ripetuto, esso si trova già (in genere) nella code cache; i dati utilizzati sono più facilmente presenti nella cache; è in generale più probabile che le istruzioni di salto condizionale siano predette correttamente, etc. Nel caso un grosso ciclo di codice non entri nella code cache, è necessario cercare di ridurne le dimensioni o ripensarlo in maniera tale da far entrare nella cache le parti eseguite più di frequente, posizionando preferibilmente le subroutines raramente usate in fondo al codice. Ad ogni modo, in un ciclo non è importante ottimizzare la prima esecuzione, ma è preferibile concentrarsi sulle iterazioni successive, che essendo ripetute un gran numero di volte moltiplicano il rallentamento provocato da un eventuale stallo.
4.4 - Generazione dell'indirizzo
Quando un'istruzione accede a dati in memoria (o comunque utilizza istruzioni che prevedono l'addressing, come LEA) è necessario calcolare l'indirizzo in cui dovrà avvenire l'accesso. Questo calcolo, se possibile, è effettuato trasparentemente durante l'esecuzione delle istruzioni precedenti. Tuttavia affinché ciò possa avvenire è necessario che tutti i registri che servono per calcolare l'indirizzo siano disponibili, e di conseguenza che non siano stati scritti dall'istruzione precedente, pena uno stallo di un ciclo di clock chiamato AGI stall (Address Generation Interlock stall). Ad esempio:
inc ecx
mov eax, [edi + ecx*4]
In questo esempio la seconda istruzione incorre in uno stallo di 1 ciclo di clock, che può essere evitato interponendo altre istruzioni che non accedano ad ecx o riscrivendo il codice come segue:
mov eax, [edi + ecx*4 + 4]
inc ecx
Si incorre allo stesso tipo di stallo anche per riferimenti impliciti a registri appena modificati, in particolare utilizzando implicitamente il registro esp in istruzioni come push, pop, call e ret dopo averlo modificato direttamente con istruzioni come add, sub, etc:
add esp, 4
pop eax ;AGI stall
Nell'esempio precedente si può evitare lo stallo sostituendo ad esempio la prima riga con pop ecx, che, sebbene modifichi implicitamente esp, non provoca AGI stall.
Gli AGI stall sono un problema solo nei processori PPlain e PMMX, mentre i processori PPro, PII, PIII e P4 soffrono di questo tipo di stalli solo negli accessi in scrittura alla memoria. In genere comunque lo stallo è trascurabile, a meno che le istruzioni successive necessitino del completamento della scrittura in memoria per essere eseguite.
Come già osservato nei paragrafi 3.1.1 e 3.1.2, i processori PPlain e PMMX dispongono di due pipeline distinte per l'esecuzione parallela, chiamate U-Pipe e V-Pipe. Ciò consente, appunto, di eseguire 2 istruzioni contemporaneamente e quindi, in condizioni ideali, di eseguire codice ad un throughput doppio. Tuttavia non tutte le istruzioni possono essere "appaiate". Queste istruzioni possono essere eseguite in pairing in una qualunque delle due pipes:
Queste invece sono pairable solo nella U-Pipe:
Infine le istruzioni di salto (condizionale e non) e l'istruzione call sono eseguibili in qualunque pipe ma pairable solo nella V-Pipe.
Affinché possa avvenire il pairing devono ovviamente essere soddisfatte determinate condizioni. Anzitutto, una istruzione deve essere eseguita ed essere pairable nella U-Pipe, l'altra nella V-Pipe. Inoltre non vi devono essere criticità nei dati (in particolare, la seconda istruzione non deve accedere a registri o dati in memoria modificati dalla prima istruzione). Eccezione a questa regola sono le coppie di istruzioni che scrivono sul registro dei flags (ad esempio add eax, ebx / inc ecx può effettuare il pairing) e quelle che modificano implicitamente esp (esempio: push ebx / push eax oppure una sequenza come push / call).
In determinate situazioni (come in presenza di AGI stall o di cache bank conflict) il pairing avviene comunque, ma la sovrapposizione temporale delle due istruzioni è solo parziale. In questo pairing imperfetto la coppia di istruzioni richiede, per essere eseguita, un tempo maggiore di ciascuna istruzione ma minore della loro somma.
Il pairing può migliorare notevolmente le prestazioni dei processori PPlain e PMMX, ma non esiste nei processori successivi grazie all'esecuzione out-of-order. In generale, è preferibile mettere tecniche di ottimizzazione obsolete in secondo piano rispetto a quelle relative a tecnologie più recenti.
Per maggiori dettagli sul pairing e sull'imperfect pairing si rimanda alla bibliografia.
Nei processori con esecuzione Out-Of-Order diventa in generale insignificante l'ordine in cui le istruzioni sono presentate al processore. Di conseguenza, ciò che è importante ai fini del miglioramento delle prestazioni è che, in qualunque momento, vi siano abbastanza istruzioni (o, per la precisione, micro-istruzioni) pronte per essere eseguite. Assumono quindi una grande importanza la fase di decoding e, ancora prima, il fetching.
La fase di decoding si occupa, appunto, di decodificare le istruzioni. Da ogni istruzione vengono generate 1 o più micro-operations (µops), che vengono poi passate alla Register Allocation Table (RAT). Essa si occupa di smistare l'uso dei registri, eventualmente allocando registri temporanei per consentire il renaming. Dal RAT le istruzioni vengono inviate al ReOrder Buffer (ROB), dove vengono riordinate ed eseguite out-of-order.
Ci sono 3 decoder: D0, D1 e D2.
Il decoder D0 è l'unico che può decodificare tutte le istruzioni possibili,
con il limite di throughput massimo di 4 µops per ciclo di clock. Gli altri due decoder
possono invece decodificare solo le istruzioni di 1 ciclo di clock e lunghe al
più 8 bytes, e lavorano solo in parallelo al D0. Affinché D1 e D2 possano
lavorare è necessario che la prima istruzione sia al più di 4 µops. Nelle
migliori condizioni il decoder può dunque generare al massimo 6 µops per
clock, comunque più di quelli che normalmente servono dato che nel processore
vengono eseguiti non più di 3 µops per ciclo di clock.
Per garantire le migliori prestazioni a livello di decoder, è consigliabile
disporre le istruzioni in maniera tale che dopo un'istruzione di diversi µops
(da 2 a 4) si intramezzino due istruzioni da 1 solo µop, le quali non
richiedono dunque tempo aggiuntivo per il decoding, essendo decodificate in
parallelo dai decoder D1 e D2. Dobbiamo dunque seguire la regola 4-1-1. Ad esempio:
mov eax, [ebp] ;1 µop, primo clock
xor eax, edx ;1 µop
add edx, [ebp+4] ;2 µop, secondo clock
add [ebp+8], ecx ;4 µop, terzo clock
Si può migliorare il codice riordinandolo in questo modo:
add [ebp+8], ecx ;4 µop, primo clock
mov eax, [ebp] ;1 µop
xor eax, edx ;1 µop
add edx, [ebp+4] ;2 µop, secondo clock
Consentendo così un throughput di decodifica di 8 µops in 2 cicli di clock, garanzia sufficiente per consentirci di dedicare ad altro la nostra attenzione.
Con il termine fetching si intende, come abbiamo visto, il prelievo delle istruzioni dalla memoria, in attesa che esse vengano decodificate.
Il codice presente nella code cache viene
prelevato a blocchi di 16 bytes allineati. Questi blocchi vengono poi inseriti
in un buffer di due blocchi da 16 bytes (per questo chiamato double
buffer). Da lì il codice viene passato al decoder in spezzoni di 16 bytes ma
non allineati, chiamati instruction fetch blocks. In questo modo quando il
codice da decodificare ha un indirizzo che non è allineato per 16, esso viene
prelevato da entrambi i blocchi del double buffer per essere inviato al decoder.
Ad ogni ciclo di clock uno solo di questi blocchi può essere caricato dalla
memoria ed inserito nel double buffer. In realtà un instruction fetch block non
è sempre lungo 16 bytes, ma può essere più corto se è presente un'istruzione
di salto, nel qual caso termina al massimo con la stessa istruzione. Ad ogni
modo, ciò può provocare dei problemi. Infatti, quando l'instruction fetch block cui appartiene un
jump non è allineato, è necessario caricare 2 blocchi allineati da 16 bytes
nel double buffer, provocando la perdita di un clock. Inoltre, quando avviene
che l'istruzione di destinazione del salto "attraversa" due 16-byte
boundaries (cioè si estende su due blocchi allineati di 16 bytes), si perde
nuovamente un ciclo di clock perché entrambi i blocchi devono essere caricati.
Chiamiamo "Decode group", cioè gruppo di decodifica, un gruppo di
istruzioni che vengono decodificate contemporaneamente, secondo le modalità
viste al punto precedente.
Dopo un'istruzione di salto, l'instruction fetch riprende di solito sull'istruzione di destinazione del salto, con tre eccezioni da tenere presenti:
In tutti questi casi l'instruction fetch dopo l'istruzione di salto è allineato ad un indirizzo multiplo di 16, e precisamente al più grande indirizzo multiplo di 16 che precede la prima istruzione dopo il salto.
Quando si ottimizza il codice, bisogna assicurarsi che il fetching e il decoding vengano effettuati (se possibile) in un numero di cicli di clock minore al numero di cicli richiesti per eseguire il codice. In queste condizioni si può essere certi che questi primi stadi della pipeline non costituiscono un problema.
Una prima cosa cui bisogna fare attenzione
quando si ottimizzano parti critiche di codice è la posizione dei vari
instruction fetch blocks. Infatti, la prima istruzione di un instruction fetch
viene sempre inviata al decoder D0 e le altre, se possibile, agli altri due
decoder; di conseguenza, quando si scrive codice seguendo la regola 4-1-1,
bisogna cercare di fare in modo che all'inizio di un instruction fetch block vi
sia un'istruzione da 4 µops.
Per ottimizzare il fetching è necessario sapere dove si trovino gli instruction
fetch blocks. Se sappiamo l'indirizzo del primo, possiamo sempre ricavarci i
successivi. Al suo indirizzo aggiungiamo infatti 16: se l'indirizzo che
otteniamo corrisponde all'offset iniziale di un'istruzione, il blocco inizierà
lì; se si trova nel mezzo di un'istruzione, il blocco successivo comincerà
all'offset iniziale di questa istruzione. Quando ci sono istruzioni di salto
(ovviamente sono esclusi i jcc not taken), possiamo ricavare l'offset
dell'instruction fetch block sfruttando le regole precedentemente elencate. In
particolare, è molto utile notare che un'istruzione che salta ad un indirizzo
multiplo di 16 forza il processore ad iniziare a quell'indirizzo un instruction
fetch block. Ciò può essere sfruttato allineando il codice di procedure
critiche e soprattutto il codice di cicli che iterano un certo numero di volte
per migliorare il fetching e per poterlo tenere sotto controllo, dato che ci
consente di determinare con certezza gli instruction fetch blocks.
A titolo esemplificativo, vediamo un esempio preso dal manuale di Agner Fog (vd bibliografia):
00401000: MOV ECX, 1000
;1 µop,
decoder D0
00401005: LL: MOV [ESI], EAX
;2 µops,
decoder D0
00401007: MOV [MEM], 0
;2 µops, decoder D0
00401011: LEA EBX, [EAX+200]
;1 µop, decoder D1
00401017: MOV BYTE PTR [ESI], 0 ;2 µops,
decoder D0
0040101A: BSR EDX, EAX
;2 µops, decoder D0
0040101D: MOV BYTE PTR [ESI+1],0 ;2 µops,
decoder D0
00401021: DEC ECX
;1 µop, decoder D1
00401022: JNZ LL
;1 µop, decoder D2
Supponiamo che un'instruction fetch block inizi all'indirizzo 401000. Allora esso dovrebbe terminare all'indirizzo 401010, che si trova all'interno dell'istruzione MOV [MEM], 0; il secondo inizia quindi all'indirizzo 401007 e finisce all'indirizzo 401017, che corrisponde all'inizio di un'istruzione. Il terzo quindi inizia all'indirizzo 401007 e completa il ciclo. In totale, nel ciclo ci sono 5 istruzioni D0, e quindi la decodifica dura 5 clocks. L'ultimo instruction fetch block contiene 3 decode group (infatti sono 3 le istruzioni che vanno nel decoder D0) e, in base alle regole viste prima, l'instruction fetch successivo inizia all'indirizzo 401005. Esso si estende quindi da 401005 a 401015, che è interno all'istruzione LEA, quindi il secondo stavolta inizia all'indirizzo 401011 e finisce all'indirizzo 401021; l'ultimo copre da 401021 in poi. Notiamo che stavolta anche l'istruzione LEA e l'istruzione DEC vengono decodificati dal decoder D0, perché si trovano all'inizio di un instruction fetch. Quindi stavolta il decoding dura 7 clocks. All'iterazione successiva, poiché l'ultimo instruction fetch contiene 1 decode group, il salto non contiene una instruction boundary e non ne contiene neanche l'istruzione di destinazione del salto, allora l'instruction fetch inizia all'indirizzo 401005. In definitiva, il decoding impiega alternativamente 5 clocks e 7 clocks, cioè in media 6 clocks. E' facile spostare qualche istruzione (o scegliere un diverso indirizzo di partenza del codice) in modo che tutte le instruction fetch boundaries cadano in istruzioni decodificate dal decoder D0, ottenendo una velocità di decoding fissa di 5 clocks per iterazione. Poiché il loop contiene 14 µops, 5 clocks è soddisfacente.
Le tecniche che possono essere usate per manipolare il fetching sono diverse. La più semplice ma non sempre sufficiente è quella di riordinare le istruzioni in un modo conveniente, oppure di spostare l'indirizzo di partenza del codice. In alternativa, si può sostituire qualche istruzione con un'altra analoga (e con lo stesso numero di µops) ma più lunga.
Come regola generale, è utile tenere presente che un loop impiega sempre per il fetching almeno un clock più del numero di blocchi di 16 bytes allineati che contiene. Se si riesce ad ottimizzare il fetching fino ad ottenere un throughput di questo tipo ci si può dedicare ad altro, dato che il fetching è senz'altro ottimale.
Queste considerazioni non valgono invece per i
processori Pentium 4 e simili, in cui vi è un unico decoder che può
decodificare una sola istruzione per ciclo di clock. Tuttavia il decoder
utilizza la cosiddetta Trace Cache (TC) per decodificare in fretta le istruzioni
eseguite più frequentemente, e che consente un throughput di 3 µops per ciclo
di clock. Unitamente al decoder principale, ciò consente di superare la
limitazione di 3 µops per ciclo di clock.
Nei Pentium 4 il decoding non è in genere un problema.
4.8 - Renaming dei registri e stalli di lettura
Nei processori Intel il renaming è stato inserito a partire dai processori Pentium Pro. Abbiamo già parlato in generale del renaming nel paragrafo 2.3.5, quindi non ci soffermiamo molto. Con il renaming vengono creati registri temporanei che consentono di eliminare le dipendenze. Ovviamente il contenuto dei registri temporanei deve prima o poi essere riportato nei registri permanenti per aggiornare lo stato del processore. Il problema è che, ad ogni ciclo di clock, si possono leggere non più di due registri permanenti. Registri che sono in attesa del write-back (ossia, appunto, dell'aggiornamento dei registri permanenti) possono essere letti senza "intasare" la RAT (Register Allocation Table) e non provocano stalli. Questa è una situazione frequente, dato che il write-back avviene in genere dopo 3 o più cicli di clock. E' importante ricordare che con il termine "registri" si intendono, in questo caso, anche i flags, i registri floating-points, MMX, etc, nonché i riferimenti impliciti ai flags o al registro ESP. Se tre µops che vengono inviati contemporaneamente richiedono di leggere più di due registri, ci sarà dunque uno stallo. Vediamo qualche esempio per chiarire le idee:
setz al
Qui viene letto un solo registro, cioè quello dei flags. AL viene solo scritto e dunque non ci interessa.
lea ebx,[ecx+edx]
add ecx,[esi+edi]
L'istruzione lea genera 1 µop che legge ecx ed edx; ebx invece viene solo scritto. add genera 2 µops e legge esi, edi ed ecx (infatti add, a differenza di mov, opera anche con il valore precedente del registro). ecx però è stato già contato per l'istruzione precedente, quindi ci sono complessivamente 4 letture dei registri, che richiedono 2 cicli di clock. Se le tre istruzioni vengono inviate al RAT contemporaneamente, non possono essere gestite in un solo ciclo di clock, ma vi sarà un ritardo di un ciclo.
A causa dell'esecuzione out-of-order è praticamente impossibile prevedere in anticipo in che ordine gli µops vengono inviati al RAT e quindi quali triplette andranno insieme. Anzitutto è quindi consigliabile seguire determinate regole che riducono la probabilità di stalli:
In particolare quest'ultimo punto può essere un po' problematico. A volte può convenire l'utilizzo di puntatori per ridurre le dimensioni del codice; ma quando c'è il rischio di read stalls, è preferibile usare indirizzi assoluti per ridurre l'uso di registri. Un "trucco" che può aiutare a risolvere problemi di questo tipo riguarda le variabili nello stack (parametri passati ad una funzione o variabili locali da essa allocate). Durante la compilazione è impossibile prevedere il valore di ESP ed EBP, ma quando il codice viene eseguito la posizione delle variabili rimane invariata, e si può dunque accedervi con indirizzi assoluti. Per far ciò si può usare del codice automodificante (SMC, Self-Modifying Code):
mov
ecx,100000
myloop:
...
add ebx,[esp+4]
xor esi,edi
...
dec ecx
jnz myloop
In questo esempio, le istruzioni add e xor accedono in lettura a 4 registri, e quindi è probabile che avvengano read stalls. Possiamo liberarci di esp riscrivendo il codice così:
lea
eax,[esp+4] ;prendiamo l'indirizzo della
variabile [esp+4]
mov [l1 + 2],eax ;e
lo mettiamo dove ci serve
mov ecx,100000
myloop:
...
l1: add ebx,[dummyaddress] ;dummyaddress
è un indirizzo qualunque
xor esi,edi
...
dec ecx
jnz myloop
Ovviamente per far ciò bisogna avere accesso in scrittura alla sezione di codice (che in Windows si può ottenere, ad esempio, con l'API VirtualProtect).
In generale, l'uso di SMC è fortemente sconsigliato da tutti i manuali. Scrivere ad un indirizzo di codice che ha già passato il fetching provoca l'annullamento dello stesso e, di conseguenza, la perdita di parecchi cicli di clock. Tuttavia, in questo caso rischiamo stalli di questo tipo solo per la prima iterazione del loop. E' invece gravemente controproducente inserire SMC all'interno di un loop, dato che ciò provocherebbe stalli ad ogni iterazione.
4.9 - Esecuzione Out-Of-Order e selezione delle istruzioni
Con l'esecuzione out-of-order, come abbiamo detto, il processore non rispetta l'ordine in cui le micro-istruzioni (µops) vengono presentato al processore: il ReOrder Buffer può contenere una coda di 40 µops, e li esegue in qualunque ordine (pur rispettando la correttezza semantica) quando ha a disposizione µops che possono essere eseguiti (e che quindi dispongono di tutte le risorse necessarie alla loro esecuzione). Il problema principale nell'ottimizzazione di processori con esecuzione out-of-order è quindi quello di assicurarsi che, in qualunque momento, il processore abbia un numero di µops sufficienti che possano essere eseguiti, condizione in cui si può assicurare il massimo throughput che le risorse hardware consentono di raggiungere. Tuttavia non tutto può essere effettuato out-of-order. Per ottimizzare al meglio, sono due le cose principali cui bisogna fare attenzione, almeno in linea di principio: ridurre il numero di µops (scegliendo quindi sequenze di codice che, seppur possibilmente qualche byte più lunghe, producono un minor numero di µops) e garantire al processore la possibilità di scegliere l'ordine degli µops.
Un primo problema riguarda le scritture in memoria. Esse infatti devono avvenire in-order: se c'è una scrittura in corso, nessun'altra scrittura in memoria può essere portata a termine prima di essa. Il processore dispone di 4 write buffers, dunque può tenere in sospeso fino ad un massimo di 4 scritture: le eventuali successive rimarranno quindi in attesa. Se si effettua un grande numero di scritture in indirizzi di memoria che non si trovano nella cache, è consigliabile interporre del codice tra una scrittura e la successiva in modo che il processore abbia qualcosa da fare per riempire i "buchi", ed è preferibile organizzare le scritture a gruppi di 4.
Il processore dispone di 5 execution ports, porte di esecuzione. Ciascuna di esse può eseguire un solo µop per ciclo di clock, mentre porte differenti possono lavorare perfettamente in parallelo. Vediamo (senza entrare troppo nei dettagli) cosa fanno queste 5 porte singolarmente:
Dunque mentre un write in memoria ha sempre
almeno 2 µops (uno alla porta 3, uno alla porta 4), un read utilizza un solo µop.
I processori Pentium 4 dispongono invece di sole 4 porte, numerate da 0 a 3
(sono accorpate in un'unica porta la 3 e la 4 che si occupano dei writes).
Inoltre le due unità ALU vengono eseguite ad una velocità doppia e quindi
possono gestire anche due µops per ciclo di clock, per un throughput ideale
massimo di 6 µops.
Un'altra cosa cui bisogna fare attenzione è il fatto che, ad ogni ciclo di clock, una execution port può eseguire un solo µop; di conseguenza, per consentire il massimo throughput (idealmente, 3 µops per ciclo di clock), è necessario che nessuna execution port riceva più di un terzo degli µops (o due terzi per le porte double speed dei Pentium 4).
La maggior parte degli µops impiega un solo ciclo di clock per essere eseguiti, mentre altri possono richiederne un numero maggiore. Ad esempio, le moltiplicazioni intere, MMX e floating point richiedono rispettivamente 4, 3 e 5 clocks. Le moltiplicazioni intere ad MMX possono comunque essere eseguite in pipeline, e ad ogni ciclo di clock può iniziare una nuova moltiplicazione (throughput = 1 moltiplicazione / clock). Le moltiplicazioni FPU hanno invece un throughput massimo di 2 per ciclo di clock. Le divisioni intere e floating point, nonché le funzioni di estrazione di radice e quelle trascendenti, richiedono fino a 40 clocks e non solo pipelined, dunque nessuna divisione può iniziare prima che la precedente sia conclusa. Tuttavia mentre viene eseguita una divisione si può consentire al processore di svolgere altro codice in parallelo.
Un grosso problema per l'esecuzione out-of-order è costituito da quelle sequenze di codice in cui ogni istruzione dipende dalla precedente, specialmente quando si eseguono istruzioni lente come moltiplicazioni o, soprattutto, divisioni. Ciò infatti impedisce al processore di eseguire le istruzioni out-of-order, limitando notevolmente il throughput. Ad esempio:
mov eax, [op1]
imul eax, [op2]
imul eax, [op3]
imul eax, [op4]
imul eax, [op5]
imul eax, [op6]
Si può migliorare il codice in questo modo:
mov eax, [op1] ;primo
accumulatore
mov ebx, [op2] ;secondo accumulatore
imul eax, [op3]
imul ebx, [op4]
imul eax, [op5]
imul ebx, [op6]
imul eax, ebx ;combiniamo i risultati
In generale, se lunghe sequenze di operazioni dello stesso tipo sono in dipendenza, conviene svolgere i calcoli separatamente su due (o più) accumulatori e combinare i risultati alla fine. Lo stesso vale anche per operazioni FPU, MMX o XMM.
I partial stalls avvengono quando si legge un registro dopo aver scritto una sua parte. Scrivendo al registro parziale, infatti, esso viene rinominato, e per poter effettuare la lettura del registro principale bisogna aspettare il retirement dell'istruzione, che normalmente impiega circa 4-5 clocks.
4.10.1 - Partial register stalls
Il tipo più comune è costituito dagli stalli parziali nei general purpose registers. Ad esempio:
mov al, byte ptr[var]
mov ebx, eax ;stallo
Un modo per evitare questo tipo di stallo è l'uso delle istruzioni movsx e movzx:
movzx ebx, byte ptr[var]
and eax, 0FFFFFF00h
or ebx, eax
Non bisogna confondersi con il procedimento opposto: se si legge una parte più piccola di un registro dopo aver modificato il registro principale, non vi è questo tipo di stallo:
mov eax, ebx
mov cl, al ;non vi è stallo
In generale, quando possibile è consigliabile
usare il registro intero piuttosto che quello parziale, onde evitare questo tipo
di problemi.
In alternativa, se è inevitabile l'uso del registro parziale, è consigliabile
settare a 0 il registro intero con l'istruzione xor
o sub. In
questo modo, infatti, il processore si "ricorda" che il registro era
azzerato e può combinare il valore del registro con il registro parziale prima
del retirement. Sono quindi del tutto sicure sequenze come:
xor eax, eax
mov al, 12
mov cl, al ;non vi è stallo
sub eax, eax
mov al, 12
mov cl, al ;non vi è stallo
Qualora non fosse possibile evitare lo stallo per altre vie, è comunque consigliabile neutralizzare il problema azzerando il registro, aggiungendo in questo modo solo 1 µop.
Anche i flags possono essere soggetti a partial stalls. Ciò avviene quando un'istruzione (tipicamente un jump condizionale) legge due o più flags dopo un'istruzione che ne modifica solo alcuni. Ad esempio:
cmp eax, ebx
inc ecx
jbe mylabel ;stallo
L'istruzione cmp
scrive su tutti i flags, mentre l'istruzione inc
non modifica il carry flag. D'altronde jbe
legge sia il carry flag che il zero flag, pertanto è necessario che le due
istruzioni precedenti siano ritirate prima di poter combinare i due flag, con il
solito stallo di 4-5 clocks.
Le istruzioni che tipicamente sono causa di partial flag stalls sono i jump
condizionali, lahf
e pushfd.
Il caso più comune è comunque quello dell'istruzione inc
(o dec)
seguito da un jump condizionale. In questi casi è preferibile utilizzare
l'istruzione add
(rispettivamente sub)
con 1 come operando immediato. add
e sub,
infatti, modificano tutti i flags, e non vi è pericolo di partial stalls
leggendo solo i flags modificati. Per sapere quali flags vengono modificati da
un'istruzione si può fare riferimento ai manuali Intel, al secondo volume in
particolare.
4.10.3 - Partial memory stalls
Sarebbe ingiusto se stalli di questo tipo non avvenissero anche quando si accede a dati in memoria di grandezze differenti... e infatti avvengono :)
Se si scrivono dati in memoria e poi se ne leggono altri di dimensione maggiore, il problema è del tutto analogo a quello dei registri:
mov byte ptr[addr], al
mov ebx, dword ptr [addr] ;stallo
A differenza dei register stalls, si ha uno stallo anche quando si leggono dati in memoria di dimensione minore dopo averne scritti di dimensione maggiore, ma solo se non si trovano allo stesso indirizzo. Dunque è sano questo codice:
mov dword ptr [addr], ebx
mov al, dword ptr [addr] ;OK
Ma non questo:
mov dword ptr [addr], ebx
mov al, dword ptr [addr+1] ;stallo
Solitamente è sempre possibile e abbastanza semplice evitare questi stalli.
4.11 - Istruzioni di salto e branch prediction
La presenza di salti è potenzialmente compromettente per le prestazioni del codice. I motivi, in generale, li abbiamo già visti nel capitolo 2, parlando delle criticità sul controllo: se il processore non sa quale sarà l'esito di un salto non può sapere da dove dovrà riprendere il fetching e l'esecuzione delle istruzioni. Allora si utilizzano tecniche di branch prediction: il processore tenta di "indovinare" l'esito del jump per poter evitare lo stallo. Se dispone informazioni su come si è comportato precedentemente un jump può farne uso per tentare di predirlo correttamente (dinamic branch prediction); altrimenti utilizza un algoritmo di static branch prediction.
Le informazioni sulla "storia" di un
jump vengono registrate nel Branch Target Buffer (BTB). Esso era di 256
entries nei PPlain. Nei PMMX la dimensione era di 256 entries, ma 16-way
set-associative. Nei processori successivi è di 512 entries e 16-way
set-associative. Un'istruzione di salto ottiene una entry nella BTB la prima
volta che viene eseguita (ma non se il salto è not taken); l'algoritmo di
sostituzione è pseudocasuale.
I meccanismi di branch prediction erano decisamente poco performanti nei PPlain,
mentre i processori successivi utilizzano meccanismi più complessi di branch
prediction, basati sul pattern recognition.
Non parleremo dei processori Pentium Plain, per concentrare la nostra attenzione su ciò che riguarda i processori successivi. Per maggiori informazioni sui Pentium Plain si rimanda alla bibliografia (specialmente ad [1]).
Lo stallo di un salto correttamente predetto dal processore è pressoché nullo; lo stallo di un salto predetto scorrettamente è di 10-20 clocks, dato che l'intera pipeline deve ripartire da capo al momento del salto.
Quando un jmp (o altre istruzioni di trasferimento) non si trova nel BTB, il processore ricorre ad algoritmi di predizione statica. Il PMMX non dispone di algoritmi di questo tipo, e suppone sempre che un salto non è nel BTB non sarà preso. I processori successivi, invece, predicono staticamente come segue:
Quando possibile, è consigliabile disporre il codice in maniera tale da trarre vantaggio della predizione statica.
4.11.2 - Predizione dinamica (e pattern recognition)
Il sistema che ha consentito di migliorare notevolmente le prestazioni di dinamic prediction rispetto ai vecchi processori è il pattern recognition. Con questo termine si intende la capacità del processore di memorizzare nel BTB il comportamento delle istruzioni di salto (not taken = 0 ; taken = 1). Il pattern formato dalle ultime 4 esecuzioni del salto stesso formerà quindi un numero binario da 0000 a 1111. Ciascuna entry della BTB dispone di 16 contatori, formati da 2 bit, in maniera tale da poter contenere un numero da 0 a 3. Quando incontra un'istruzione di salto che è nella BTB, il processore sceglie l'indice del contatore da modificare in base al pattern degli ultimi 4 esiti dell'istruzione (ad esempio se l'istruzione è stata rispettivamente Not Taken, Taken, Taken, Not Taken, il pattern sarà 0110 e il processore accederà al contatore 6), e lo incrementa se l'istruzione di salto è taken, lo decrementa se l'istruzione di salto è not taken. Ovviamente se un contatore è a 0 non viene più decrementato, mentre se è a 3 non viene incrementato. Il processore predice come taken un jump se il contatore contiene 2 o 3; come not taken se contiene 0 o 1. Facciamo un esempio. Supponiamo che un jump abbia il seguente pattern ripetitivo:
11001100110011001100110011001100...
Osserviamo che la sequenza 1100 è sempre seguita da 1, 1001 è sempre seguita da 1, 0011 è sempre seguita da 0, 0110 è sempre seguita da 0. Dopo l'iniziale periodo in cui il BTB viene "addestrato" (e in cui è inevitabile quale predizione errata), i contatori 12 e 9 arriveranno nello stato 3, mentre i contatori 3 e 6 giungeranno ad essere azzerati. A questo punto, la predizione sarà sempre corretta finché il jump mantiene lo stesso pattern.
Il periodo di "addestramento" dei contatori del BTB dura 2 periodi, ossia 6 esecuzioni per un pattern di lunghezza 3, 8 per uno di lunghezza 4, etc.
Questo sistema di branch prediction è in grado di predire correttamente tutti i pattern con un periodo di lunghezza minore o uguale a 5, nonché molti pattern di lunghezza superiore (consultare [1] per una lista dettagliata), e può gestire molto bene (talvolta anche al 100%) i pattern quasi regolari, cioè quelli che, di tanto in tanto, presentano una deviazione dal pattern ripetuto. Se un jump segue alternativamente due pattern completamente differenti, il processore impara entrambi i pattern e può predire correttamente la maggior parte dei jump.
Salti e chiamate indirette non dispongono di pattern recognition. Esse vengono predette come l'ultima volta che sono state eseguite. Lo stesso vale per le istruzioni JECXZ e LOOP.
Il Return Stack Buffer (RSB) è un array di 16 entries (4 nei PMMX) utilizzato per la predizione delle istruzioni RET. Esso funziona come uno stack (dunque con il sistema LIFO, Last-In First-Out). Quando viene eseguita una call, il return address viene inserito nel RSB; al conseguente return esso viene prelevato dallo stack ed utilizzato per la predizione. Ciò è necessario dato che una subroutine può essere chiamata da varie zone di codice.
Questo sistema suggerisce alcune regole di programmazione: non bisogna mai uscire da una subroutine o chiamarla con un'istruzione jump, altrimenti si perderebbe la corrispondenza tra calls e returns; bisogna evitare che ci siano più di 16 calls in rapida successione, perché alcune non potranno entrare nel RSB. Ciò è particolarmente frequente in calls ricorsive. Può essere conveniente trasformare una funzione ricorsiva in una iterativa, o comunque assicurarsi che non ci siano più di 16 ricorsioni.
I salti sono un fattore particolarmente delicato dell'ottimizzazione. E' consigliabile, quando ciò è possibile, riorganizzare il codice in maniera tale da rispettare la predizione statica (collocando il codice che verrà eseguito più di frequente immediatamente dopo il jump condizionale e quello che verrà eseguito raramente più lontano nel codice), ed eliminare jumps non necessari, anche a costo di duplicare piccole parti di codice. Ad esempio:
test eax,eax
jz L2
L1: mov ecx, ebx
jmp L3
L2: mov ecx, edx
L3: xor ecx, esi
ret
Si può migliorare questo codice così:
test eax,eax
jz L2
L1: mov ecx, ebx
xor ecx, esi
ret
L2: mov ecx, edx
xor ecx, esi
ret
Un altro strumento per evitare l'uso dei jump condizionali è fornito dalle istruzioni SETcc e CMOVcc (introdotta però solo a partire dai processori Pentium Pro) nonché dall'uso di alcuni tricks per manipolare i flags. Ad esempio, per scegliere il minore tra eax ed ebx, anziché un cmp e un jcc, si può operare come segue (a = eax, b = ebx):
sub ebx, eax ;ebx = b -
a (setta il CF se b < a)
sbb ecx, ecx ;ecx = -1 se b < a, ecx = 0
altrimenti
and ecx, ebx ;ecx = b - a se b < a, ecx = 0 altrimenti
add eax, ecx ;eax = a + (b-a) = b se b < a, eax = a + 0
= a altrimenti
Per un esempio dell'istruzione CMOVcc, riprendiamo il codice di prima:
test eax,eax
jz L2
L1: mov ecx, ebx
xor ecx, esi
ret
L2: mov ecx, edx
xor ecx, esi
ret
Possiamo eliminare definitivamente anche questo salto in questo modo:
test eax,eax
mov ecx,ebx
cmovz ecx,edx
xor ecx, esi
ret
sebbene in questo caso è possibile evitare
l'uso di cmovz
con un trick analogo a quello di prima con sbb.
Esercizio per il lettore :)
Per accertarsi che il processore supporti i conditional moves si può utilizzare
l'istruzione cpuid.
Le parti di codice che più frequentemente hanno bisogno di ottimizzazione sono in assoluto i loops. Per la loro stessa natura, essi iterano infatti migliaia, milioni o miliardi di volte, e ciò comporta che perdere un clock ad ogni iterazione significa perderne complessivamente migliaia, milioni, miliardi.
Le tecniche che si utilizzano per ottimizzare i loop sono quelle viste finora: migliore impostazione degli accessi in memoria per migliorare l'hit rate della cache, analisi del fetching e del decoding, accurata selezione delle istruzioni e miglioramento dell'esecuzione out-of-order, eliminazione dei salti e corretta branch prediction.
Un modo che spesso consente di ottimizzare parecchio il codice di un ciclo è il cosiddetto loop unrolling (traducendo: srotolamento). Per piccoli cicli può essere utile adottare un unrolling totale. Ad esempio:
mov
eax, 12345678h
mov ecx, 6
mov edi, offset buffer
myloop: xor dword ptr[edi], eax
add edi, 4
sub ecx, 1
jnz myloop
Qui ci sono solo 6 iterazioni, dunque non vale la pena di sprecare registri (i contatori) e inserire branches che, come abbiamo visto, è sempre meglio evitare. Possiamo quindi riscrivere il codice così:
mov
eax, 12345678h
mov edi, offset buffer
xor dword ptr[edi], eax
xor dword ptr[edi+4], eax
xor dword ptr[edi+8], eax
xor dword ptr[edi+12], eax
xor dword ptr[edi+16], eax
xor dword ptr[edi+20], eax
L'uso di edi come puntatore ed eax per memorizzare la costante è giustificato dalla riduzione delle dimensioni del codice che ciò comporta.
Quando, come spesso accade, non si può effettuare l'unrolling totale perché il numero di iterazioni è troppo elevato, si può effettuare l'unrolling parziale. Svolgere l'unrolling di un loop di un fattore n significa riscrivere il codice per svolgere, ad ogni iterazione, n operazioni anziché una. L'unrolling ci consente di ridurre il numero di branches, di eliminare le dipendenze che impedirebbero l'esecuzione parallela o out-of-order e di poter riorganizzare il codice per evitare problemi di vario genere.
Si può effettuare l'unrolling ipoteticamente per qualsiasi fattore n. Di fatto, però, è sconveniente scegliere n che non sia una potenza di due; solitamente si effettuano 2 o 4 operazioni per iterazione.
Quando si "unrolla" di un fattore n, il nuovo ciclo può evidentemente effettuare un numero di operazioni che sia multiplo di n (precisamente, n * il numero di iterazioni). Se il numero di operazioni è multiplo di n, non ci sono problemi. Altrimenti è necessario svolgere un certo numero di operazioni fuori (in genere appena prima) dal ciclo. Se x è il numero complessivo di operazioni, il numero di operazioni che vanno calcolate fuori dal ciclo è x MOD n, ossia il resto della divisione di x per n.
Facciamo un esempio (tratto da [6]). Supponiamo di avere il seguente algoritmo in C:
double a[MAX_LENGTH], b[MAX_LENGTH];
for (i=0; i < MAX_LENGTH; i++)
{
a[i] = a[i] + b[i];
}
In assembly potremmo tradurlo in questo modo:
mov ecx, MAX_LENGTH
mov eax, offset A
mov ebx, offset B
ALIGN 16
;allineiamo per il fetching
add_loop:
fld qword ptr [eax] ;len = 3 1 µop
fadd qword ptr [ebx] ;len = 3 2 µops
fstp qword ptr [eax] ;len = 3 2 µops
add eax,
8 ;len = 3 1 µop
add ebx,
8 ;len = 3 1 µop
dec
ecx
;len = 1 1 µop
jnz add_loop ;len
= 2 1 µop
Questo codice non è sicuramente ottimale. Notiamo che abbiamo addirittura 3 contatori: eax ed ebx che servono da puntatori e ecx che è il contatore vero e proprio. Possiamo sfruttare ecx per tutti e 3 i compiti:
mov ecx, MAX_LENGTH
shl ecx, 3
;moltiplichiamo per 8
lea eax, [origine + ecx] ;i puntatori puntano alla fine del loop e
non all'inizio!
lea ebx, [destinazione + ecx]
neg ecx
;cambiamo il segno di ecx
ALIGN 16
add_loop:
fld qword ptr [eax + ecx] ;len = 3 1 µop
fadd qword ptr [ebx + ecx] ;len = 3 2 µops
fstp qword ptr [eax + ecx] ;len = 3 2 µops
add ecx, 8
;len = 3 1 µop
jnz add_loop
;len = 2 1 µop
Solitamente ecx viene decrementato fino a raggiungere 0. Qui invece è più comodo partire da un numero negativo e incrementare di 8, cosicché possiamo utilizzarlo per "aggiustare" i puntatori. In questo modo possiamo ridurre sia la dimensione del loop (18 bytes prima, 14 ora), sia il numero di µops (8 prima, 7 ora).
Avendo allineato il loop a 16 bytes, il fetching è sicuramente adeguato: infatti il loop occupa solo 14 bytes, e quindi è sufficiente un instruction fetch block. Osserviamo inoltre che, poiché il loop è interamente dentro un unico blocco allineato di 16 bytes, il fetching dura almeno 2 clocks, che quindi rappresenta un tetto minimo sotto il quale non è possibile scendere.
Possiamo invece migliorare il decoding. Non ci sono problemi per il Pentium 4, ma per i processori precedenti non è del tutto ottimale, poiché 3 istruzioni vanno nel decoder D0 e quindi ci vogliono 3 cicli di clock. D'altronde non c'è neanche un modo immediato per evitare ciò: l'istruzione che vorremmo spostare è fld qword ptr [eax + ecx], che genera 1 solo µop ma va nel decoder D0 perché è la prima dell'instruction fetch block. Possiamo però sfruttare un metodo intelligente: mettiamo fld alla fine del loop, e lo utilizziamo ad ogni iterazione per caricare i dati dell'iterazione successiva; tuttavia, poiché non guadagniamo nulla collocando alla fine tre istruzioni consecutive da 1 µop ciascuna, spostiamo l'add qualche riga più su:
mov ecx, MAX_LENGTH
shl ecx, 3
lea eax, [origine + ecx]
lea ebx, [destinazione + ecx]
neg ecx
fld qword ptr [eax + ecx] ;carichiamo il primo dato necessario
ALIGN 16
add_loop:
fadd qword ptr [ebx + ecx] ;len = 3 2 µops
porta 0, porta 2
add ecx,8
;len = 3 1 µop porta
0/1
fstp qword ptr [eax + ecx-8] ;len = 4 2 µops
porta 3, porta 4
fld qword ptr [eax + ecx] ;len = 3 1 µop
porta 2
jnz add_loop
;len = 2 1 µop porta
1
fstp qword ptr [eax + ecx] ;neutralizziamo il fld in più
Raggiungendo i 2 clocks anche nel decoding.
Non vi è la possibilità di register read stalls: i registri cui si accede in lettura sono eax, ebx, ecx, st(0) e i flags. Tuttavia sia gli accessi in lettura a st(0) che quello ai flags avvengono sempre previa scrittura, e quindi non sono un problema. Anche gli accessi ad ecx sono sicuri in quanto esso è modificato abbastanza spesso, quindi le uniche due letture di registri contemporanee possono essere quelle ad eax ed ebx.
Gli µops sono ben distribuiti, e il tempo di esecuzione è anche minore di due cicli di clock.
L'unico problema effettivo è il retirement (ossia il salvataggio del risultato dell'esecuzione): esso deve avvenire in-order, e possono essere ritirati 3 µops per ciclo di clock; il ciclo è 7 µops, dunque il retirement dura 7/3 = 2.33 clocks, che si arrotonda all'intero successivo, cioè 3.
Dunque il ciclo impiega complessivamente 3 clock per iterazione.
Effettuiamo l'unrolling per 2:
mov ecx, MAX_LENGTH
lea eax, [origine]
lea ebx, [destinazione]
test ecx,1
jz pari
fld qword ptr [eax]
fadd qword ptr [ebx]
fstp qword ptr [eax]
pari:
lea eax, [eax + ecx*8] ;i puntatori puntano alla fine del loop
lea ebx, [eax + ecx*8]
and ecx, -2 ;azzeriamo il bit meno significativo
shl ecx, 3
neg ecx
;cambiamo il segno di ecx
ALIGN 16
add_loop:
fld qword ptr [eax + ecx] ;len = 3
1 µop porta 2
fadd qword ptr [ebx + ecx] ;len = 3
2 µops porta 0, porta 2
fstp qword ptr [eax + ecx] ;len = 4
2 µops porta 3, porta 4
fld qword ptr [eax + ecx + 8] ;len = 4
1 µop porta 2
fadd qword ptr [ebx + ecx + 8] ;len = 4
2 µops porta 0, porta 2
fstp qword ptr [eax + ecx + 8] ;len = 4
2 µops porta 3, porta 4
add ecx, 16
;len = 3 1 µop
porta 0/1
jnz add_loop
;len = 2 1 µop
porta 1
Per lo stesso problemino di decoding di prima possiamo trasformare così il loop:
fld qword ptr [eax + ecx]
ALIGN 16
add_loop:
fadd qword ptr [ebx + ecx] ;len = 3 2 µops
porta 0, porta 2
fstp qword ptr [eax + ecx] ;len = 4 2 µops
porta 3, porta 4
add ecx, 16
;len = 3 1 µop
porta 0/1
fld qword ptr [eax + ecx - 8] ;len = 4 1 µop
porta 2
fadd qword ptr [ebx + ecx - 8] ;len = 4
2 µops
porta 0, porta 2
fstp qword ptr [eax + ecx - 8] ;len = 4
2 µops
porta 3, porta 4
fld qword ptr [eax + ecx] ;len = 3 1 µop
porta 2
jnz add_loop
;len = 2 1 µop
porta 1
fstp qword ptr [eax + ecx] ;neutralizziamo il
fld in più
Da notare che questi accorgimenti servono a poco se gli accessi in memoria non sono nella cache, così da ritardare parecchio l'esecuzione del codice.
4.13 - Identificare il processore
Abbiamo visto che ci sono molte differenze tra una famiglia e l'altra di processori, o anche tra un singolo processore e un altro. Per quale è conveniente ottimizzare? La risposta a questa domanda è opinabile. Personalmente ritengo logico scrivere codice che giri decentemente su tutte le piattaforme, ma ponendo particolare occhio ai processori più recenti. Inutile spendere ore per ottimizzare per un PPlain, meglio dedicarsi ad ottimizzazioni più proficue.
Scrivendo un programma, non possiamo sapere in anticipo su quale piattaforma dovrà girare. E' quindi preferibile scrivere codice che sia sufficientemente ottimizzato per tutti i processori, che quindi non contenga ottimizzazioni specifiche per un tipo di processore a discapito di processori diversi, specie se il miglioramento non è particolarmente sensibile.
Tuttavia, può succedere di voler ottimizzare al massimo particolari spezzoni di codice e assicurarsi che girino al meglio delle loro potenzialità su tutti i processori. In questo caso, la cosa migliore è di scrivere il codice per ciascuno dei processori a cui è destinato, e decidere a runtime tramite l'istruzione CPUID.
L'istruzione CPUID è stata introdotta nei processori 486. Se si vuole essere sicuri che l'istruzione sia supportata dal processore (ma secondo me non ne vale la pena), si può usare codice di questo tipo:
pushfd
pop
eax
;preleviamo i flags in eax
mov ebx,
eax
;salviamo il valore in ebx
xor eax, 1000000000000000000000b ;inverte il bit 21
push eax
popfd
;proviamo a modificare
pushfd
;prendiamo il nuovo valore
pop eax
xor
eax,ebx
;xor con il vecchio valore
test eax, 1000000000000000000000b ;controlla il bit 21: se è 0 allora CPUID non
è supportata
jz NoCpuid
L'istruzione CPUID riceve in input il valore di eax e restituisce tutte le informazioni che riguardano il processore in eax, ebx, ecx ed edx. In particolare, se eax = 1, CPUID ritorna in edx le informazioni riguardanti le caratteristiche del processore (feature flags). In tutti i flags ritornati in edx, 1 indica che una determinata caratteristica è supportata, 0 che non lo è. Ad esempio, il feature flag che segnala il supporto per l'istruzione CMOVcc è il 15, cui si accede quindi con questo codice:
mov eax,1
cpuid
test edx, 1000000000000000b ;controlla il quindicesimo bit
jz NoCmov
;se è zero, niente CMOVcc :(
I feature flag della FPU, delle estensioni MMX, SSE ed SSE2 sono rispettivamente lo 0, il 23, il 25 ed il 26.
Per ulteriori informazioni sull'istruzione CPUID consultare la bibliografia, in particolare il secondo manuale Intel.
In questo paragrafo parleremo delle regole di programmazione generali, quali istruzioni evitare, e trucchi vari per migliorare l'efficienza del codice. Non spero di fornire una trattazione esauriente, ma mi propongo di ampliare questa sezione nel corso del tempo.
4.14.1 - Istruzione XCHG
L'istruzione XCHG,
che scambia il contenuto di due registri oppure di un registro e una locazione
di memoria, viene talvolta utilizzata al posto dell'istruzione MOV
per spostare un registro in un altro. Ad esempio al posto di MOV
EAX, EBX viene utilizzato XCHG
EAX, EBX se non ci interessa conservare il
valore di EBX.
Ciò consente di risparmiare un byte, ma è assolutamente da evitare se si vuole
scrivere codice ottimizzato, in quanto l'istruzione XCHG
è lenta se comparata con l'istruzione MOV.
Anche la forma XCHG register, [memory]
dovrebbe essere evitata, in quanto il processore si comporta come se fosse
presente il prefisso LOCK,
impedendo l'uso della memoria cache.
4.14.2 - Istruzioni JECXZ e LOOP
Queste due istruzioni sono complesse e dovrebbero essere sostituite da istruzioni più semplici. Al posto di JECXZ si può utilizzare TEST ECX, ECX / JZ, mentre al posto di LOOP è consigliabile utilizzare SUB ECX, 1 / JNZ (su processori precedenti al Pentium 4 è preferibile DEC ECX, che non provoca partial stall dato che il JZ legge solo il Zero Flag; vd paragrafo 4.14.5).
4.14.3 - Istruzioni ENTER e LEAVE
Queste due istruzioni generano molti più µops delle sequenze analoghe e dovrebbero quindi essere evitate.
4.14.4 - Istruzioni di manipolazione delle stringhe
Tutte le istruzioni di manipolazione delle stringhe (MOVS, CMPS, STOS, LODS) sono lente se sono senza il prefisso di ripetizione, e dovrebbero essere sostituite con istruzioni semplici. REP MOVSD e REP STOSD sono molto veloci se:
In queste condizioni il processore può muovere un'intera cacheline per ciclo di clock.
Le istruzioni REP LODSD, REP SCASD e REP CMPSD non sono molto veloci ed è consigliabile sostituirle con dei loops.
4.14.5 - INC e DEC
Le istruzioni INC e DEC possono provocare partial stalls e devono quindi assolutamente essere sostituite da ADD e SUB in tali occasioni. Anche in assenza di partial stalls, però, esse sono meno performanti delle istruzioni analoghe nei processori Pentium 4 e nei successivi processori con architettura Intel NetBurst. E' quindi preferibile l'utilizzo di ADD e SUB, sebbene siano forme più lunghe (3 bytes).
4.14.6 - Shift e rotazioni
Shift e rotazioni hanno nei Pentium 4 un throughput di 1 istruzione per ciclo di clock ma una latenza di ben 4 clocks. Secondo i manuali Intel, se uno shift a sinistra ha un contatore minore o uguale a 3 è conveniente sostituirlo con una sequenza di add:
shl ebx,3
Può essere sostituito con:
add ebx, ebx
add ebx, ebx
add ebx, ebx
Secondo dei test che ho effettuato nel mio Intel Celeron 2.00 Ghz, sembrerebbe che la sequenza di add è più efficiente dello shift a sinistra anche se il contatore è minore o uguale a 6.
Anche l'istruzione ror/rol soffre dello stesso problema (specie se il contatore è un registro o è un immediato maggiore di 1), e dovrebbe possibilmente essere evitata.
Se la latenza non è un problema è comunque preferibile utilizzare lo shift.
4.14.7 - Moltiplicazioni e divisioni per potenze di 2
Anziché dividere o moltiplicare per potenze di due, è molto conveniente utilizzare le istruzioni SHL e SHR (moltiplicazione e divisione unsigned), SAL e SAR (moltiplicazione e divisione signed). Moltiplicare o dividere per 2n equivale infatti a shiftare rispettivamente a sinistra o a destra di n bit. Esempi:
shr eax, 5 ;divide per
32 (unsigned)
sar eax, 5 ;divide per 32 (signed)
shl eax, 3 ;moltiplica eax per 8
C'è da notare una differenza tra l'istruzione SAR e l'istruzione IDIV: se il risultato di una divisione di un numero negativo non è intero, IDIV arrotonda all'intero successivo (quello più vicino a 0), mentre SAR all'intero precedente. Ad esempio, se EAX contiene -5, dopo SAR EAX, 1 conterrà -3, mentre dopo IDIV EAX, 2 conterrà -2.
Infine per avere il resto della divisione unsigned per 2n si può utilizzare l'istruzione AND, che ci consente di selezionare gli n bit meno significativi:
and eax, 2n - 1
4.14.8 - Moltiplicazioni intere
Una moltiplicazione intera (con MUL o IMUL) impiega 4 cicli di clock (3 nei Pentium 4). E' quindi spesso conveniente effettuare la moltiplicazione sfruttando sequenze di istruzioni aritmetiche semplici come LEA, ADD, SUB ed SHL. Esempi:
lea eax, [eax * 2 + eax] ;moltiplica eax * 3
lea eax, [eax * 4 + eax] ;moltiplica eax * 5
add eax,
eax ;
lea eax, [eax * 2 + eax] ;moltiplica eax * 6
mov ebx,
eax ;ebx
= eax
shl eax,
3
;eax = eax * 8
sub eax,
ebx ;moltiplica
eax per 7
lea eax, [eax * 8 + eax] ;moltiplica eax * 9
add
eax,eax
;ebx = eax * 2
lea eax, [eax * 4 + eax] ;moltiplica eax * 10
lea ebx, [eax * 4 + eax] ;ebx
= eax * 5
shl eax,
4
;eax = eax * 16
sub eax,
ebx ;moltiplica
eax * 11
add eax,
eax ;eax
= eax * 4
lea eax, [eax * 2 + eax] ;moltiplica eax * 12
Nei Pentium 4 non è consigliabile utilizzare l'istruzione LEA con lo scaled index (cioè la moltiplicazione per 2, 4 od 8), in quanto viene generato un µop per effettuare lo shift, che ha una latenza maggiore della rispettiva sequenza di add. Ad esempio, per moltiplicare per 11, si può riscrivere il codice precedente così:
lea ebx, [eax + eax] ;NON
lea ebx, [eax * 2]!
add ebx,
eax ;ebx
= 3x
add eax,
eax ;eax
= 2x
add eax,
eax ;eax
= 4x
add eax,
eax ;eax
= 8x
add eax,
ebx ;eax
= 11x
Il difetto di questo sistema è che aumenta notevolmente il numero di µops. Tuttavia nei Pentium 4 le istruzioni aritmetiche vengono eseguite a velocità doppia, pertanto questo codice impiega sicuramente, nel complesso, molto meno del codice precedente con lo shift implicito.
4.14.9 - Divisioni intere senza segno per una costante
Le divisioni sono tra le operazioni più complicate per il processore. Una divisione può impiegare da 19 a 39 clocks, a seconda delle dimensioni dell'operando e del tipo di processore. Se il divisore è una costante, si può applicare un algoritmo (preso dal manuale di Agner Fog) che consente di utilizzare una moltiplicazione anziché una divisione. Poiché una moltiplicazione ha un throughput di soli 3-4 cicli di clock, ciò consente un miglioramento non da poco.
Sia d il divisore. Allora:
b = (numero di bit significativi di d) - 1
r = 32 + b
f = 2r / d
Se f è intero, allora vai ad A
Se f non è intero e la sua parte frazionaria è < 0.5, allora vai a B
Se f non è intero e la sua parte frazionaria è > 0.5, allora vai a C
A: d = 2b
risultato = x SHR b
B:
risultato = ((x+1) * (f arrotondato all'intero precedente)) SHR r
C:
risultato = (x * (f arrotondato all'intero successivo)) SHR r
Facciamo un esempio: supponiamo di dividere per 7. Allora:
(7)10 = (111)2, quindi b
= 3-1 = 2
r = 32 + b = 34
f = 234 / 7 = 2454267026,28...
La parte frazionaria di f è 0,28 < 0,5, quindi usiamo l'algoritmo B:
risultato = ((x + 1) * 2454267026) SHR 34
Cioè, in assembler:
inc eax
mov edx, 2454267026 ;2454267026 = intero più vicino ad f
mul edx
shr edx, 2 ;2 = b
E in edx abbiamo il risultato della divisione. Questo algoritmo non funziona solo se x = 0FFFFFFFFh. Se anche quello è un valore possibile per il dividendo, si può procedere così:
mov edx, 2454267026
add eax, 1 ;NON va bene inc eax, che non setta il carry flag!
jc overflow
mul edx
overflow:
shr edx, 2
Il jc è predetto scorrettamente solo se x = 0FFFFFFFFh, quindi aggiunge poco o niente al tempo di esecuzione.
Da notare che il valore di r può anche essere scelto diversamente. In questo caso il risultato della divisione è corretto se x < 2r-b, ma generalmente scorretto per gli altri valori. Un valore particolarmente comodo è r = 32 che ci consente di evitare lo shift su edx. Nell'esempio precedente, poiché b = 2, se siamo certi che x < 2^32-2 = 230 = 1073741824 possiamo ripetere l'algoritmo ottenendo:
f = 232 / 7 = 613566756,57... > 0,5 ===> usiamo l'algoritmo C
risultato = (x * 613566757) SHR 32
Cioè, traducendo in linguaggio assembler:
mov edx, 613566757
mul edx
Si può utilizzare lo stesso algoritmo anche se il divisore è noto solo a runtime ma è costante, nel senso che tutte le divisioni utilizzano lo stesso divisore.
4.14.10 - Massimo e minimo tra due interi
Per scegliere il minimo tra due interi abbiamo già visto un buon algoritmo:
;eax = a \
ebx = b
sub ebx, eax ;ebx = b -
a (setta il CF se b < a)
sbb ecx, ecx ;ecx = -1 se b < a, ecx = 0
altrimenti
and ecx, ebx ;ecx = b - a se b < a, ecx = 0 altrimenti
add eax, ecx ;eax = a + (b-a) = b se b < a, eax = a + 0
= a altrimenti
;risultato in eax
Così per il massimo:
;eax = a \
ebx = b
sub ebx, eax ;eax = b - a (setta il CF se
b < a)
sbb ecx, ecx ;ecx = -1 se b < a, ecx = 0
altrimenti
and ecx, ebx ;ecx = b - a a se b < a, ecx = 0 altrimenti
sub eax, ecx ;ebx = b - (b-a) = a se b < a, ebx = b - 0
= b altrimenti
;risultato in ebx
Utilizzando l'istruzione CMOVcc possiamo migliorare ancora.
Minimo:
;eax = a \
ebx = b
cmp eax, ebx ;setta il carry flag se eax
< ebx
cmovnc eax, ebx ;eax = ebx se eax < ebx
;risultato in eax
Viceversa per il massimo:
;eax = a \
ebx = b
cmp eax, ebx ;setta il carry flag se eax <
ebx
cmovc eax, ebx ;eax = ebx se eax < ebx
;risultato in eax
4.14.11 - Valore assoluto di un intero
Un modo efficiente per ottenere il valore assoluto di eax è il seguente:
cdq
xor eax, edx
sub eax, edx
Per chi volesse approfondire, ecco le fonti principali delle informazioni contenute in questo tutorial. Consiglio soprattutto il manuale [1] di Agner Fog.
[1] - "How to optimize for the Pentium
family of microprocessors" di Agner Fog, reperibile http://www.agner.org/assem.
[2] - "Intel Architecture Optimization Manual" order number 242816.
[3] - "Intel Architecture Optimization Reference Manual" order number 245127.
[4] - "Intel Architecture Software
Developer Manual" volumi 1, 2 e 3, order numbers 245470, 245471, 245472.
[5] - "Intel Pentium 4 and Intel Xeon Processor Optimization"
order number 248966-007.
[6] - "AMD Athlon Processor - x86 Code Optimization Guide".
[7] - Patterson, Hennessy, "Struttura, organizzazione e progetto dei calcolatori", Jackson Libri.
[8] - "The Art of Assembly Language", Chapter 25.
[9] - "Hyper-Threading Technology
Architecture and Microarchitecture", http://www.intel.com/technology/itj/2002/volume06issue01/vol6iss1_hyper_threading_technology.pdf
[10] - www.google.it :)
Spider
|
Note finali |
Ringrazio albe la cui pazienza per fornirmi materiale è stata preziosissima e Quequero che ha posto le basi affinché completassi questo tutorial che, altrimenti, avrei abbandonato.
|
Disclaimer |
Vorrei ricordare che il processore va comprato e non rubato, e quindi vale la pena di sfruttarlo al massimo!
Capitoooooooo????? Bhè credo di si ;))))